Lesson Contents
Queuing mechanisms like LLQ are about managing the front of our queues. RED (Random Early Detection) is about managing the tail of our queue.
When a queue is full, there is no room for any more packets and the router drops packets that should have been queued. This is called tail drop.
Data traffic is usually bursty so when tail drop occurs, the router probably drops multiple packets. Tail drop is bad, especially for TCP traffic.
The TCP window size increases automatically but when TCP segments are dropped, it reduces back to one segment. The window size then grows exponentially until it reaches half the window size of what it was when the congestion occurred. The TCP window size then grows linearly. This process is called slow start and explained in detail in the TCP window size scaling lesson.
The problem with this behavior of TCP is that you probably don’t have just one TCP connection but multiple TCP connections. When the queue is full and tail drop occurs, everything is discarded and all TCP connections use slow start. We call this TCP global synchronization and it looks like this:
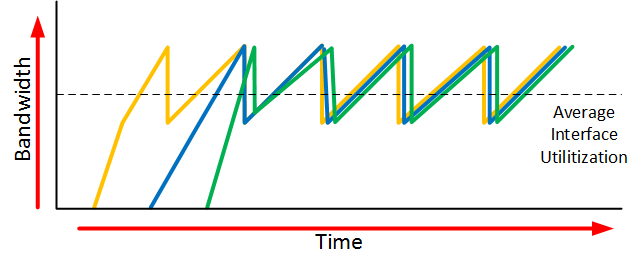
To increase overall throughput, we can use a technique called RED (Random Early Detection). Instead of waiting for tail drop to happen, we monitor the queue depth. When the queue starts to fill up, we discard some random packets with the goal of slowing down TCP. The “weighted” part of WRED is that WRED monitors the average queue depth. When the queue starts to fill, it will only drop a few random packets. When the queue length increases, it becomes more aggressive and drops even more random packets until it hits a certain limit. When this limit is reached, all packets are dropped.
Here’s how to visualize this:
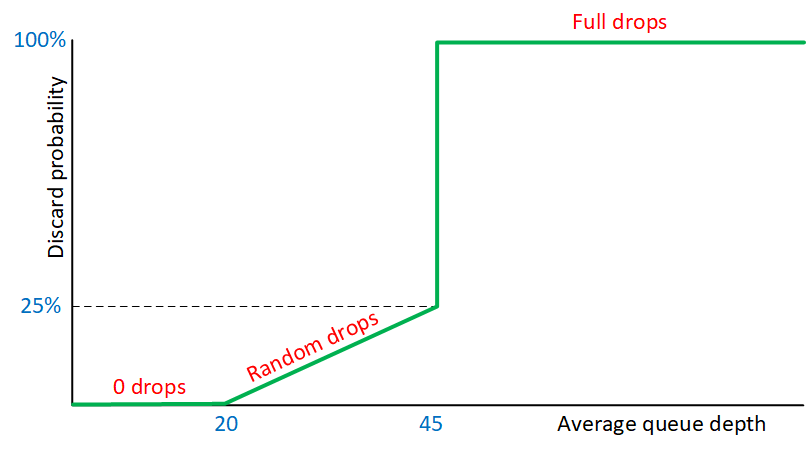
This graph has an X and Y axis:
- Average queue depth: this is the length of our queue and for now, let’s say this represents the number of packets in the queue.
- Discard probability: the chance in % that WRED drops our packets.
What do the different numbers mean? WRED uses a traffic profile for the packet drop probability based on the following three items:
- Minimum threshold: 20 packets
- Maximum threshold: 45 packets
- MPD (Mark Probability Denominator): 25%
These values can be configured of course.
Here’s how it works:
- When the average queue depth is below the minimum threshold (20), WRED doesn’t drop any packets at all.
- When the average queue depth is above the minimum threshold (20), WRED starts to drop a small number of random packets.
- When the average queue depth increases even further, WRED drops a larger % of random packets until we reach the maximum threshold (45).
- When the average queue depth reaches the maximum threshold (45), WRED drops all packets.
- The MPD (25%) is the number of packets that WRED drops when we hit the maximum threshold (45).
We can summarize this in a table:
| Average queue depth | Action | WRED action name |
| average queue depth < minimum threshold | No packets are dropped. | No drop |
| average queue depth > minimum threshold AND average queue depth < maximum threshold | Percentage of packets is dropped. This percentage increases to a maximum (MPD) until we reach the maximum threshold. | Random drop |
| Average queue depth > maximum threshold | All packets are dropped. This is the same as tail drop. | Full drop |
Dropping all packets when we hit an artificial maximum threshold might sound weird. How is that any better than “regular” tail drop?
Some packets are more important than others so instead of dropping completely random packets, we use different traffic profiles for different packets. We can discard packets based on criteria like the CoS, IP Precedence, DSCP, and some other options.
Here is a quick example of two traffic profiles:
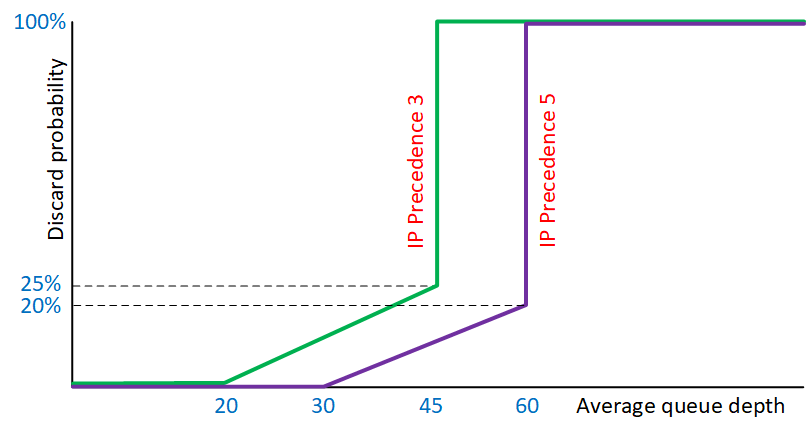
Above, we have two different traffic profiles. One for packets marked with IP precedence 3 and another one for IP precedence 5:
- IP Precedence 3:
- minimum threshold: 20 packets
- maximum threshold: 45 packets
- MPD: 25%
- IP Precedence 5:
- minimum threshold: 30 packets
- maximum threshold: 60 packets
- MPD: 20%
We drop IP precedence 3 packets earlier (minimum threshold 20 packets) and more often (MPD 25%) than IP precedence 5 packets.
Instead of IP precedence, we can also use DSCP. WRED then sets a minimum threshold based on the drop probability that we have seen in the IP precedence and DSCP values lesson:
Hello Rene,
Thank you very much for the lesson.
but I’m still a little bit confused, Please, correct me if I’m wrong:
based on the command below if it’s set AF probability will be considered:
random-detect dscp-basednow if we have AF21 and AF33 the class different but the probability of dropping packet from AF33 more than AF21, correct?
what about if the packets AF21 and AF31? what about if we have AF21 and EF and CS3 and CS4?
also what is the meaning for fair-queue command? what is the impact when you are using it in the policy map?
Thank you,
Samer Abbas
Adding I’m looking for the drop probability for these Marking if they are in the same Policy Map with
random-detect dscp-basedThanks,
Samer
Hello Samer
Class 4 has the highest priority, so if you have AF33, it will have a lower drop probability than AF21 for example. But within the same class, the higher the number the higher the drop probability, so AF13 will more likely be dropped compared to AF11. So yes, you are correct.
... Continue reading in our forumHi There,
can explain me the average size calculation in WRED. Is queue size calculated based on the bandwidth available to the specific queue or total available bandwidth of link ?
Regards,
Ranganna
Hello Ranganna
When WRED calculates the average queue size, it does so by calculating the actual size of the real queue. Specifically, the average is calculated periodically every few milliseconds. It uses the following formula:
https://cdn-forum.networklessons.com/uploads/default/original/2X/4/49dee3e66a13cca56dab8dce4c14e612f03c090d.png
The maximum size of the physical queue will depend on what kind of interface we’re talking about and what p
... Continue reading in our forum