Lesson Contents
When it comes to redistribution, there are a lot of things that potentially could go wrong. Two possible issues are sub-optimal routing and routing loops. All redistribution problems boil down to two different issues:
- Metric related problems.
- Administrative distance related problems.
If you haven’t seen my first lesson on metric related redistribution problems then I would recommend to start there first. Once you know how to fix metric issues, this lesson will be easier to understand.
In this lesson we will take a look at redistribution problems that are caused by the administrative distance. I’ll also show you why this occurs and of course how to fix it!
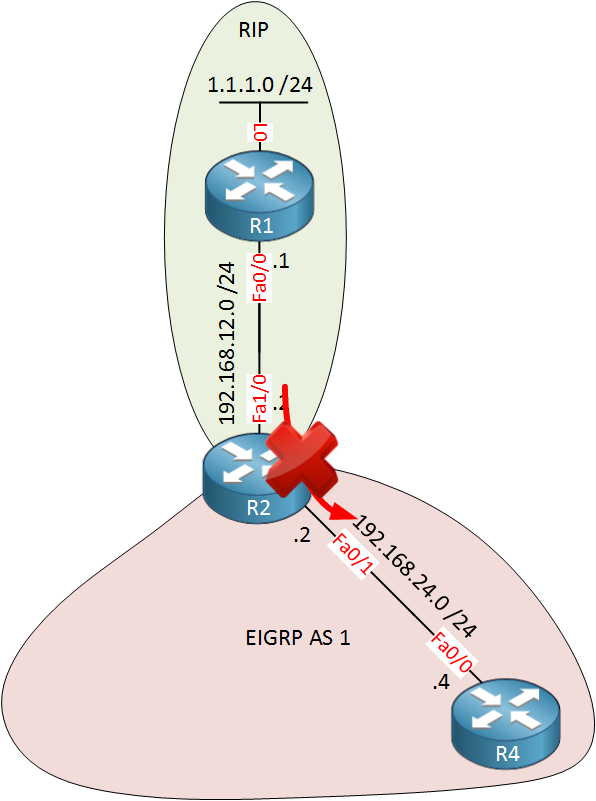
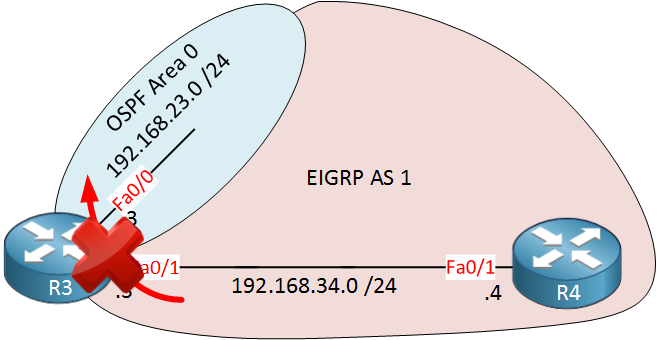
This is the topology I will use:
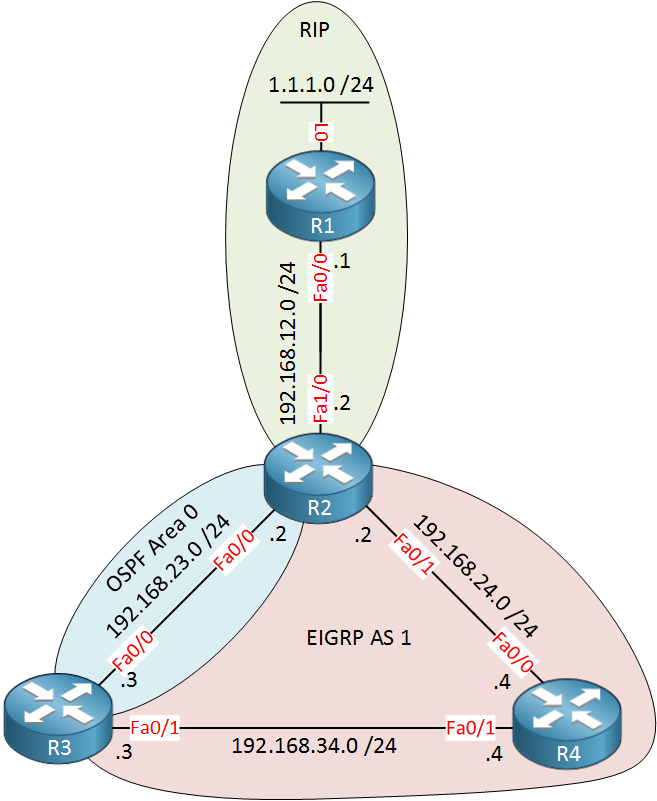
Above we have 4 routers, let me explain this topology:
- R1 runs RIP and is only used to inject a prefix into the topology (1.1.1.0 /24).
- R2 runs RIP, OSPF and EIGRP. We will perform redistribution on this router in a bit.
- R3 runs OSPF and EIGRP, it will also be configured for redistribution.
- R4 runs only EIGRP.
Here’s what the configuration of the routing protocols look like:
R1#show running-config | section rip
router rip
version 2
network 1.0.0.0
network 192.168.12.0
no auto-summaryR2#show running-config | section rip
router rip
version 2
network 192.168.12.0
no auto-summary
R2#show running-config | section ospf
router ospf 1
log-adjacency-changes
network 192.168.23.0 0.0.0.255 area 0
R2#show running-config | section eigrp
router eigrp 1
network 192.168.24.0
no auto-summaryR3#show running-config | section ospf
router ospf 1
log-adjacency-changes
network 192.168.23.0 0.0.0.255 area 0
R3#show running-config | section eigrp
router eigrp 1
network 192.168.34.0
no auto-summaryR4#show running-config | section eigrp
router eigrp 1
network 192.168.24.0
network 192.168.34.0
no auto-summaryAnd here’s what the routing tables look like, we haven’t configured redistribution yet:
R2#show ip route
C 192.168.12.0/24 is directly connected, FastEthernet1/0
1.0.0.0/24 is subnetted, 1 subnets
R 1.1.1.0 [120/1] via 192.168.12.1, 00:00:28, FastEthernet1/0
C 192.168.24.0/24 is directly connected, FastEthernet0/1
C 192.168.23.0/24 is directly connected, FastEthernet0/0
D 192.168.34.0/24 [90/307200] via 192.168.24.4, 00:00:33, FastEthernet0/1R2 learns a prefix from R1 through RIP and it learns about the network in between R3 and R4 (192.168.34.0 /24). Let’s take a look at R3:
R3#show ip route
D 192.168.24.0/24 [90/307200] via 192.168.34.4, 00:01:23, FastEthernet0/1
C 192.168.23.0/24 is directly connected, FastEthernet0/0
C 192.168.34.0/24 is directly connected, FastEthernet0/1R3 learns about the network (192.168.24.0 /24) in between R2 and R4 through EIGRP. Let’s check R4:
R4#show ip route
C 192.168.24.0/24 is directly connected, FastEthernet0/0
C 192.168.34.0/24 is directly connected, FastEthernet0/1R4 didn’t learn anything so far. It’s an internal EIGRP router and the only two interfaces that are advertised in EIGRP are directly connected for R4.
Configurations
Want to follow along with this example? Here you will find the startup configuration of each device.
R1
hostname R1
!
interface Loopback0
ip address 1.1.1.1 255.255.255.0
!
interface FastEthernet0/0
ip address 192.168.12.1 255.255.255.0
!
router rip
no auto-summary
network 192.168.12.0
network 1.1.1.0
!
endR2
hostname R2
!
interface FastEthernet0/0
ip address 192.168.23.2 255.255.255.0
!
interface FastEthernet0/1
ip address 192.168.24.2 255.255.255.0
!
interface FastEthernet1/0
ip address 192.168.12.2 255.255.255.0
!
router rip
no auto-summary
network 192.168.12.0
!
router eigrp 1
network 192.168.34.0
network 192.168.24.0
!
router ospf 1
network 192.168.23.0 0.0.0.255 area 0
!
endR3
hostname R3
!
interface FastEthernet0/0
ip address 192.168.23.3 255.255.255.0
!
interface FastEthernet0/1
ip address 192.168.34.3 255.255.255.0
!
router eigrp 1
network 192.168.34.0
!
router ospf 1
network 192.168.23.0 0.0.0.255 area 0
!
endR4
hostname R4
!
interface FastEthernet0/0
ip address 192.168.24.4 255.255.255.0
!
interface FastEthernet0/1
ip address 192.168.34.4 255.255.255.0
!
router eigrp 1
no auto-summary
network 192.168.34.0
network 192.168.24.0
!
endRedistribution Configuration
To achieve full connectivity, we have to configure redistribution. However, let’s say that we have some requirements…something you could encounter on a CCIE R&S lab exam:
- Configure redistribution between RIP and EIGRP on R2 only.
- Configure redistribution between OSPF and EIGRP on R3 only.
When we configure redistribution like that, we should have full connectivity. Take a look at the diagram below:
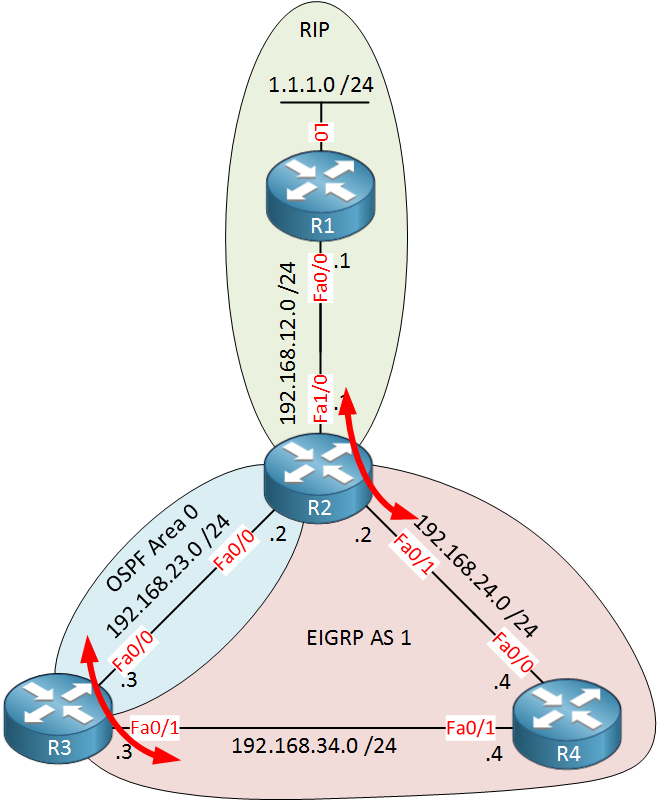
Above you can see where we will perform redistribution. Let’s be brainless and configure redistribution without thinking too much about this topology:
R2(config)#router rip
R2(config-router)#redistribute eigrp 1 metric 1
R2(config)#router eigrp 1
R2(config-router)#redistribute rip metric 1000 100 255 1 1500R2 is now redistributing between RIP and EIGRP. Let’s configure R3:
R3(config)#router eigrp 1
R3(config-router)#redistribute ospf 1 metric 1500 100 255 1 1500
R3(config)#router ospf 1
R3(config-router)#redistribute eigrp 1 subnetsEasy enough! Redistribution has been configured so we should have full connectivity right? We should check if everything is reachable…
Reachability Verification
When you configure redistribution and your goal is to have full connectivity then you should try pinging all IP addresses in the topology. A quick method to do this is to fetch all IP addresses using show ip aliases and then use a TCLSH script. Here’s how to do it:
R1#show ip aliases
Address Type IP Address Port
Interface 1.1.1.1
Interface 192.168.12.1R2#show ip aliases
Address Type IP Address Port
Interface 192.168.12.2
Interface 192.168.23.2
Interface 192.168.24.2R3#show ip aliases
Address Type IP Address Port
Interface 192.168.23.3
Interface 192.168.34.3R4#show ip aliases
Address Type IP Address Port
Interface 192.168.24.4
Interface 192.168.34.4This gives us a nice overview of all IP addresses. Copy / paste them in notepad and then turn it into a simple TCLSH script, then run it on all routers. To reduce the output, I removed all the succesful pings and only kept the failed pings:
R1(tcl)#foreach address {
+>(tcl)#1.1.1.1
+>(tcl)#192.168.12.1
+>(tcl)#192.168.12.2
+>(tcl)#192.168.23.2
+>(tcl)#192.168.24.2
+>(tcl)#192.168.23.3
+>(tcl)#192.168.34.3
+>(tcl)#192.168.24.4
+>(tcl)#192.168.34.4
+>(tcl)#} { ping $address repeat 3 }
Sending 3, 100-byte ICMP Echos to 192.168.23.2, timeout is 2 seconds:
...
Success rate is 0 percent (0/3)
Type escape sequence to abort.
Sending 3, 100-byte ICMP Echos to 192.168.23.3, timeout is 2 seconds:
...
Success rate is 0 percent (0/3)
R1(tcl)#R1 can ping everything with the exception of 192.168.23.2 and 192.168.23.3. That’s the link in between R2 and R3. Let’s make a mental note of this and continue with the other routers:
R2(tcl)#foreach address {
+>(tcl)#1.1.1.1
+>(tcl)#192.168.12.1
+>(tcl)#192.168.12.2
+>(tcl)#192.168.23.2
+>(tcl)#192.168.24.2
+>(tcl)#192.168.23.3
+>(tcl)#192.168.34.3
+>(tcl)#192.168.24.4
+>(tcl)#192.168.34.4
+>(tcl)#} { ping $address repeat 3 }
Type escape sequence to abort.
Sending 3, 100-byte ICMP Echos to 1.1.1.1, timeout is 2 seconds:
...
Success rate is 0 percent (0/3)
R2(tcl)#R2 is able to reach everything with the exception of 1.1.1.1. Make a mental note of this and continue:
R3(tcl)#foreach address {
+>(tcl)#1.1.1.1
+>(tcl)#192.168.12.1
+>(tcl)#192.168.12.2
+>(tcl)#192.168.23.2
+>(tcl)#192.168.24.2
+>(tcl)#192.168.23.3
+>(tcl)#192.168.34.3
+>(tcl)#192.168.24.4
+>(tcl)#192.168.34.4
+>(tcl)#} { ping $address repeat 3 }
Type escape sequence to abort.
Sending 3, 100-byte ICMP Echos to 1.1.1.1, timeout is 2 seconds:
...
Success rate is 0 percent (0/3)
R3(tcl)#R3 has the same issue as R2. What about R4?
R4(tcl)#foreach address {
+>(tcl)#1.1.1.1
+>(tcl)#192.168.12.1
+>(tcl)#192.168.12.2
+>(tcl)#192.168.23.2
+>(tcl)#192.168.24.2
+>(tcl)#192.168.23.3
+>(tcl)#192.168.34.3
+>(tcl)#192.168.24.4
+>(tcl)#192.168.34.4
+>(tcl)#} { ping $address repeat 3 }
Type escape sequence to abort.
Sending 3, 100-byte ICMP Echos to 1.1.1.1, timeout is 2 seconds:
...
Success rate is 0 percent (0/3)
R4(tcl)#We see that R1 has some issues and that R2, R3 and R4 are unable to reach 1.1.1.1. Let’s focus on these last three routers first.
R2 is learning network 1.1.1.0 /24 directly from R1 through RIP, there’s nothing in between these two routers. Let’s take a quick look at the routing table of R2:
R2#show ip route
C 192.168.12.0/24 is directly connected, FastEthernet1/0
C 192.168.24.0/24 is directly connected, FastEthernet0/1
C 192.168.23.0/24 is directly connected, FastEthernet0/0
D 192.168.34.0/24 [90/307200] via 192.168.24.4, 01:03:07, FastEthernet0/1Depending on when you check the routing table, you might or might not see an entry for 1.1.1.0 /24. Above you can see that it’s gone…a few seconds later this is what I see:
R2#show ip route
C 192.168.12.0/24 is directly connected, FastEthernet1/0
1.0.0.0/24 is subnetted, 1 subnets
O E2 1.1.1.0 [110/20] via 192.168.23.3, 00:00:02, FastEthernet0/0
C 192.168.24.0/24 is directly connected, FastEthernet0/1
C 192.168.23.0/24 is directly connected, FastEthernet0/0
D 192.168.34.0/24 [90/307200] via 192.168.24.4, 01:03:45, FastEthernet0/1Interesting, R2 now has an OSPF entry for network 1.1.1.0 /24. If you would check the routing tables of R3 and R4 you will see 1.1.1.0 /24 appearing and disappearing as well.
It is kinda annoying to check the routing tables of all these routers just to “hunt” for some routes that dissapear like a thief in the night, especially when we have a large topology. There are a couple of useful tools that we can use that help us.
The first one is route profiling. This tells us how often there are changes to the routing table. You have to enable it first before you can look at the results:
R2,R3 & R4#
(config)#ip route profileLet it run for a couple of minutes and you will see results:
R2#show ip route profile
IP routing table change statistics:
Frequency of changes in a 5 second sampling interval
-------------------------------------------------------------
Change/ Fwd-path Prefix Nexthop Pathcount Prefix
interval change add change change refresh
-------------------------------------------------------------
0 975 983 1165 983 1165
1 16 182 0 182 0
2 174 0 0 0 0
3 0 0 0 0 0
4 0 0 0 0 0
5 0 0 0 0 0
Route profiling works by checking the routing table with a 5 second interval. The changes to the routing table are categorized in:
- Fwd-path change: the number of changes in the forwarding path. This value is an accumulation of prefix-add, next-hop change and pathcount.
- Prefix add: new prefix has been added to the routing table.
- Nexthop change: the next hop of a prefix has changed.
- Pathcount change: the number of paths in the routing table has changed.
- Prefix refresh: this is standard routing table maintenance, prefixes are refreshed every now and then. No changes to the routing table have been made.
The output of route profiling is not very easy to read. Let me explain it:
- The column on the left (Change / interval) is the frequency. For example the value of 182 in row 1 means that in 182 intervals, one prefix has been added.
- The value of 174 in row 2 means that we had 174 intervals where the forward path changed two times.
- The value of 1165 in row 0 means that we had 1165 intervals where the next hop did not change.
If you see a lot of intervals in row 1 or higher then we know something is going on and that the routing table is unstable. Here’s what R3 and R4 look like:
R3#show ip route profile
IP routing table change statistics:
Frequency of changes in a 5 second sampling interval
-------------------------------------------------------------
Change/ Fwd-path Prefix Nexthop Pathcount Prefix
interval change add change change refresh
-------------------------------------------------------------
0 987 987 1170 1170 1170
1 183 183 0 0 0
2 0 0 0 0 0
3 0 0 0 0 0
4 0 0 0 0 0
5 0 0 0 0 0
R4#show ip route profile
IP routing table change statistics:
Frequency of changes in a 5 second sampling interval
-------------------------------------------------------------
Change/ Fwd-path Prefix Nexthop Pathcount Prefix
interval change add change change refresh
-------------------------------------------------------------
0 837 837 1021 1021 1021
1 184 184 0 0 0
2 0 0 0 0 0
3 0 0 0 0 0
4 0 0 0 0 0
5 0 0 0 0 0
Here we see something similar to R2, there have been quite some intervals where one prefix has changed.
Now we know something is going on but we still don’t know what. Enabling a debug will help:
R2, R3 & R4#debug ip routing
IP routing debugging is onNow we can see in real-time what is happening to the routing table. Let’s take a look at R2:
R2#
RT: add 1.1.1.0/24 via 192.168.12.1, rip metric [120/1]
RT: NET-RED 1.1.1.0/24
Periodic IP routing statistics collection
RT: closer admin distance for 1.1.1.0, flushing 1 routes
RT: NET-RED 1.1.1.0/24
RT: add 1.1.1.0/24 via 192.168.23.3, ospf metric [110/20]
RT: NET-RED 1.1.1.0/24
Periodic IP routing statistics collection
RT: del 1.1.1.0/24 via 192.168.23.3, ospf metric [110/20]
RT: delete subnet route to 1.1.1.0/24
RT: NET-RED 1.1.1.0/24
RT: delete network route to 1.0.0.0
RT: NET-RED 1.0.0.0/8Take a close look at the output above, this debug gives us a lot of valuable information. Let me describe what is happening to R2:
- R2 learns prefix 1.1.1.0 /24 from R1 through RIP and adds it to its routing table.
- R2 learns prefix 1.1.1.0 /24 from R3 through OSPF.
- R2 removes the RIP entry for 1.1.1.0 /24 and installs the OSPF entry.
- R2 deletes the OSPF entry for 1.1.1.0 /24 from the routing table.
This is very interesting, I’ll describe in a minute why this is happening…let’s first take a look at R3 and R4:
R3#
RT: add 1.1.1.0/24 via 192.168.34.4, eigrp metric [170/2636800]
RT: NET-RED 1.1.1.0/24
RT: delete route to 1.1.1.0 via 192.168.34.4, eigrp metric [170/2636800]
RT: no routes to 1.1.1.0
RT: NET-RED 1.1.1.0/24
RT: delete subnet route to 1.1.1.0/24
RT: NET-RED 1.1.1.0/24
RT: delete network route to 1.0.0.0
RT: NET-RED 1.0.0.0/8R3 learns 1.1.1.0 /24 through EIGRP and then deletes this entry from its routing table…interesting, what about R4?
R4#
RT: add 1.1.1.0/24 via 192.168.24.2, eigrp metric [170/2611200]
RT: NET-RED 1.1.1.0/24
RT: delete route to 1.1.1.0 via 192.168.24.2, eigrp metric [170/2611200]
RT: no routes to 1.1.1.0
RT: NET-RED 1.1.1.0/24
RT: delete subnet route to 1.1.1.0/24
RT: NET-RED 1.1.1.0/24
RT: delete network route to 1.0.0.0
RT: NET-RED 1.0.0.0/8R4 has the same issue, it installs the 1.1.1.0 /24 prefix that it learned from R2 and then deletes it from the routing table. So what exactly is going on here? Let me explain this story step-by-step with some images.
AD Based Redistribution Problem
Let’s describe the problem step-by-step. In the beginning, R2 redistributes network 1.1.1.0 /24 that it has learned from R1 through RIP into EIGRP:
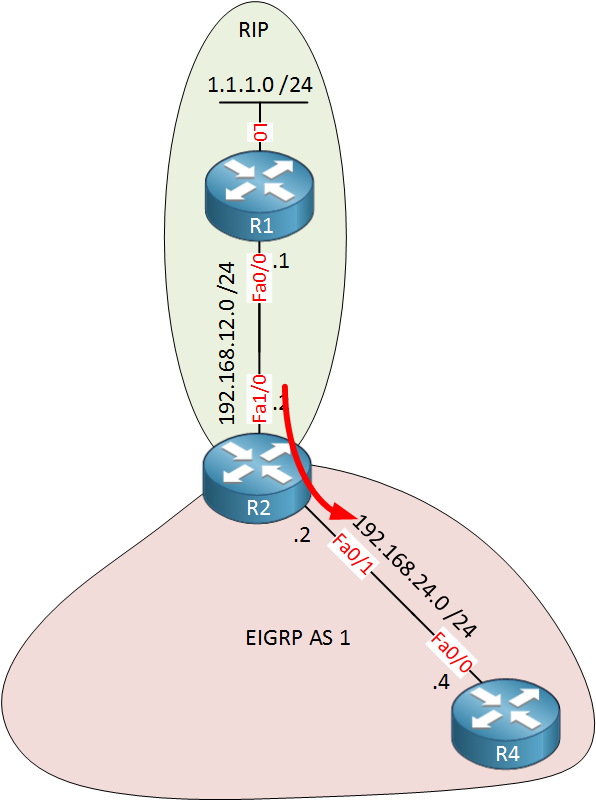
R4 learns the prefix and is now able to advertise it to R3 through EIGRP. R3 will redistribute the prefix into OSPF:

R2 now has a decision to make:
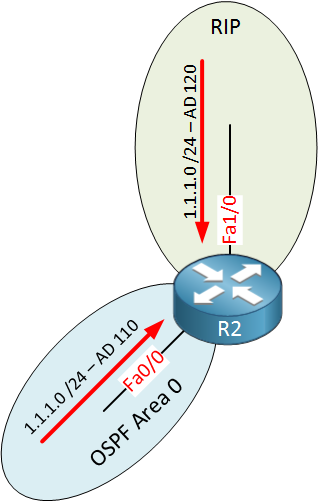
R2 has two sources for 1.1.1.0/24. The correct RIP route from R1 and the incorrect OSPF route from R3. It will select the route from R3 since the AD of OSPF is lower than RIP.
As a result, R2 will remove the RIP entry from its routing table and now it is no longer able to redistribute 1.1.1.0 /24 from RIP into EIGRP:
Since R2 doesn’t have a RIP entry for 1.1.1.0 /24, there’s nothing to redistribute into EIGRP. R4 and R3 will remove their EIGRP entry for 1.1.1.0 /24 from their routing tables and R3 is now unable to redistribute 1.1.1.0 /24 into OSPF:
R2 won’t learn about 1.1.1.0 /24 through OSPF anymore and after a short while, R2 will install the RIP entry for 1.1.1.0 /24 again its routing table and the whole problem repeats itself. This problem that I just described is an administrative distance based redistribution problem. R2 is installing incorrect routing information in its routing table because the administrative distance is lower.
Before we start talking about solutions, let me get back to the issue with R1 that was unable to ping 192.168.23.2 and 192.168.23.3.
To understand why this doesn’t work, take a look at the routing table of R2:
R2#show ip route connected
C 192.168.12.0/24 is directly connected, FastEthernet1/0
C 192.168.24.0/24 is directly connected, FastEthernet0/1
C 192.168.23.0/24 is directly connected, FastEthernet0/0On R2, network 192.168.23.0 /24 is directly connected and not advertised directly in RIP. It has been advertised in OSPF and R3 redistributes this network into EIGRP so that R4 can learn about it.
R2 however won’t install this in its routing table since it already has an entry (directly connected). Because of this, R1 won’t learn about this network. You could fix this by using a network command or redistribute connected under the RIP process on R2.
Back to our problem with network 1.1.1.0 /24…before we start looking at solutions, let’s think about the “core” issue of our problem.
In our particular scenario, R2 learned network 1.1.1.0 /24 from RIP which has an AD of 120, let’s call this the “internal route“.
After redistribution, R2 learns about 1.1.1.0 /24 through OSPF. Let’s call this the “external route”.
The problem is that R2 should never accept the external route, it should always prefer the internal route. This is a redistribution rule that you should follow:
If R2 would prefer it’s internal route from RIP instead of the external route from OSPF then we wouldn’t have any problems. Are there any other scenarios where something like this could occur?
- RIP doesn’t have a clue about “internal” and “external” routes, it’s all the same so it’s vulnerable to selecting the wrong route.
- OSPF uses the same AD for internal and external routes but it always gives preference to internal routes.
- EIGRP uses a different AD for internal and external routes.
Whenever your internal route has a higher AD than the external route, you have to be careful! Some examples:
- The internal route was learned through RIP (AD 120) and the external route is learned through OSPF (AD 110).
- The internal route was learned through EIGRP external (AD 170) and the external route is learned through RIP (AD 120).
- The internal route was learned through BGP internal (AD 200) and the external route is learned through OSPF (AD 110).
Now let’s take a look at some solutions!
Hi Rene,
You explained the subject in a very detailed manner. Thanks a lot . No one actually have explained it like the way you done. Thanks a lot
Ammar,
CCIE R&S - in progress
Thanks Ammar!
Hi Rene,
Why when you redistribute ospf into eigrp by default the network 192.168.23.0/24 is not show up in the eigrp table on R4 even if you have the “network 192.168.23.0” command under ospf process? It requires to also apply redistribute connected under eigrp on R3 so it can show up on R4.
Hi Sergio,
When you redistribute OSPF into EIGRP then it should advertise 192.168.23.0/24 to R4. You don’t have to redistribute connected, that’s only needed when the network is not advertised in OSPF.
Rene
Hi Rene,
I discussed this with my study group and we came to find out that I was not entering the metric when redistributing ospf into eigrp. In order for connected/networks to redistribute from another routing protocol into eigrp I would need to specify the metric unless is eigrp into eigrp. Thanks for your response.