Lesson Contents
RIP uses a couple of timers to do its work:
- Update: this is how often we send routing updates, the default is 30 seconds.
- Invalid: the number of seconds since we received the last valid update, once this timer expires the route goes into holddown, the default is 180 seconds.
- Holddown: the number of seconds that we wait before we accept any new updates for the route that is in holddown, the default is 180 seconds,
- Flush: how many seconds since we received the last valid update until we throw the route away, the default is 240 seconds.
In this lesson, we’ll take a look at these times in action. We will use the following topology for this:
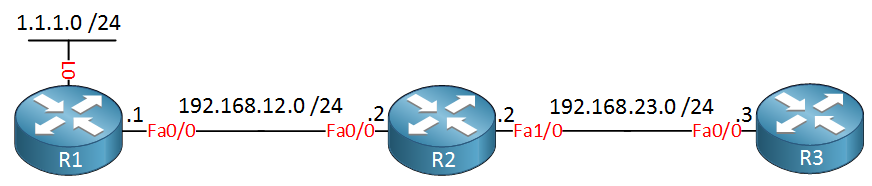
Above we have three routers that are running RIP. On R1 we have a loopback interface that will be advertised in RIP.
Configuration
Here’s the configuration of all three routers:
R1#show running-config | section rip
router rip
version 2
network 1.0.0.0
network 192.168.12.0
no auto-summaryR2#show running-config | section rip
router rip
version 2
network 192.168.12.0
network 192.168.23.0
no auto-summaryR3#show running-config | section rip
router rip
version 2
network 192.168.23.0
no auto-summaryYou can see the default RIP times with the show ip protocols command:
R2#show ip protocols | include seconds
Sending updates every 30 seconds, next due in 21 seconds
Invalid after 180 seconds, hold down 180, flushed after 240Before we start messing around, let’s enable some debugging on R2 and R3:
R2 & R3
#debug ip rip
RIP protocol debugging is on
#debug ip routing
IP routing debugging is onThe RIP debugs will give us information about incoming and outgoing updates, the IP routing debug will tell us when something is installed or remove from the routing table.
Let’s mess around now!
Default Behavior
We will start with a pretty straight forward example where we use default timers. At the moment R1 is advertising 1.1.1.0 /24 to R2, here is the output of the routing tables:
R2#show ip route rip
1.0.0.0/24 is subnetted, 1 subnets
R 1.1.1.0 [120/1] via 192.168.12.1, 00:00:15, FastEthernet0/0R3#show ip route rip
1.0.0.0/24 is subnetted, 1 subnets
R 1.1.1.0 [120/2] via 192.168.23.2, 00:00:06, FastEthernet0/0
R 192.168.12.0/24 [120/1] via 192.168.23.2, 00:00:06, FastEthernet0/0Let’s wreak some havoc and take down R1:
R1(config)#interface FastEthernet 0/0
R1(config-if)#shutdownOnce we do this, R2 will no longer receive any updates from R1. At this moment the invalid and flush timer will increase. In the first 180 seconds, nothing will happen:
R2#show ip route 1.1.1.0
Routing entry for 1.1.1.0/24
Known via "rip", distance 120, metric 1
Redistributing via rip
Last update from 192.168.12.1 on FastEthernet0/0, 00:01:12 ago
Routing Descriptor Blocks:
* 192.168.12.1, from 192.168.12.1, 00:01:12 ago, via FastEthernet0/0
Route metric is 1, traffic share count is 1After 180 seconds the invalid timer will have expired and the holddown timer starts. We can see this in the debug:
R2#
Sep 3 15:42:58.235: RT: delete route to 1.1.1.0 via 192.168.12.1, rip metric [120/1]
Sep 3 15:42:58.235: RT: no routes to 1.1.1.0, entering holddownNow when you look at the routing table, here’s what you will see:
R2#show ip route rip
1.0.0.0/24 is subnetted, 1 subnets
R 1.1.1.0/24 is possibly down,The 1.1.1.0 /24 will remain in the routing table of R2 but it says it’s “possibly down”. At this moment, R2 will send an update (route poison) to R3:
R2#
Sep 3 15:43:00.235: RIP: build flash update entries
Sep 3 15:43:00.235: 1.1.1.0/24 via 0.0.0.0, metric 16, tag 0
Sep 3 15:43:00.235: RIP: sending v2 flash update to 224.0.0.9 via FastEthernet0/1 (192.168.23.2)
Sep 3 15:43:00.235: RIP: build flash update entries
Sep 3 15:43:00.235: 1.1.1.0/24 via 0.0.0.0, metric 16, tag 0R2 is informing R3 that this network is gone, here’s what R3 thinks of it:
R3#
Sep 3 15:42:58.147: RIP: received v2 update from 192.168.23.2 on FastEthernet0/0
Sep 3 15:42:58.147: 1.1.1.0/24 via 0.0.0.0 in 16 hops (inaccessible)
Sep 3 15:42:58.147: RT: del 1.1.1.0 via 192.168.23.2, rip metric [120/2]
Sep 3 15:42:58.147: RT: delete subnet route to 1.1.1.0/24When R3 receives the update it will remove 1.1.1.0 /24 immediately from the routing table:
R3#show ip route rip
R 192.168.12.0/24 [120/1] via 192.168.23.2, 00:00:07, FastEthernet0/0R3 will also send an update to R2 (poison reverse):
R3#
Sep 3 15:43:00.147: RIP: sending v2 flash update to 224.0.0.9 via FastEthernet0/0 (192.168.23.3)
Sep 3 15:43:00.147: RIP: build flash update entries
Sep 3 15:43:00.147: 1.1.1.0/24 via 0.0.0.0, metric 16, tag 0We can verify that R2 receives the poison reverse:
R2#
Sep 3 15:43:02.239: RIP: received v2 update from 192.168.23.3 on FastEthernet0/1
Sep 3 15:43:02.239: 1.1.1.0/24 via 0.0.0.0 in 16 hops (inaccessible)60 seconds later after the route went in holddown, we will see something on the console of R2:
R2#
Sep 3 15:43:58.235: RT: delete subnet route to 1.1.1.0/24And the 1.1.1.0/24 is now finally gone from the routing table…
R2#show ip route rip
Wait a minute…how come this route got removed after 60 seconds? Shouldn’t it be 180 seconds (the default holddown timer)? This is very confusing indeed. What happens is that the invalid (180 seconds) and the flush timer (240 seconds) start at the same time. Once the invalid timer expires, the holddown timer starts running…60 seconds later, the flush timer is expired and the route is removed from the routing table.
Because of this, the holddown timer is only active for 60 seconds, not 180 seconds. Here’s an image to help you visualize this:
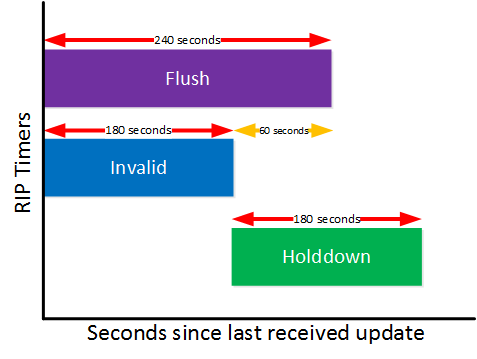
So now you have seen what happens when R2 stops receiving updates from R1. What do you think happens when R1 comes during the holddown timer period? Let’s find out…
Lower metric from R1 during holddown time
There are a number of different scenarios. When 1.1.1.0 /24 is in holddown, R1 can come back online and advertise the same, a higher or lower metric. Let’s see what happens when it comes back with a lower metric than before. To test this, we’ll use an offset-list on R1:
R1(config)#interface FastEthernet 0/0
R1(config-if)#no shutdown
R1(config)#router rip
R1(config-router)#offset-list 0 out 10We’ll bring R1 back online with a higher metric. Here’s what R2 looks like now:
R2#show ip route rip
1.0.0.0/24 is subnetted, 1 subnets
R 1.1.1.0 [120/11] via 192.168.12.1, 00:00:10, FastEthernet0/0Now we will shut the interface on R1 again and we’ll wait till the route goes in holddown:
R1(config)#interface FastEthernet 0/0
R1(config-if)#shutdownAfter 180 seconds, we’ll see the holddown message again:
R2#
Sep 3 15:54:58.263: RT: delete route to 1.1.1.0 via 192.168.12.1, rip metric [120/11]
Sep 3 15:54:58.263: RT: no routes to 1.1.1.0, entering holddownWhile the route is in holddown, I quickly enable the interface on R1 again and reduce the metric:
R1(config)#interface FastEthernet0/0
R1(config-if)#no shutdown
R1(config)#router rip
R1(config-router)#offset-list 0 out 5Let’s see what R2 thinks of this…
R2#
Sep 3 15:55:38.555: RIP: received v2 update from 192.168.12.1 on FastEthernet0/0
Sep 3 15:55:38.555: 1.1.1.0/24 via 0.0.0.0 in 6 hops
Sep 3 15:55:38.555: RT: updating rip 1.1.1.0/24 (0x0): via 192.168.12.1 Fa0/0R2 has received the update from R1 and sees the new hop count. Does it install it in the routing table?
R2#show ip route rip
1.0.0.0/24 is subnetted, 1 subnets
R 1.1.1.0/24 is possibly down,Unfortunately not, R2 doesn’t care about it at all…the route remains in holddown. In most textbooks you will read that when RIP receives an update for a route that has an equal or lower metric then it should use this information and get the route out of holddown, this seems not to be the case. I did some research on this and it seems some ancient IOS versions have this behavior. I tested this on IOS 15 and this is how it behaves…the router won’t budge…
60 seconds later, the flush timer will expire and the route will be flushed:
R2#
Sep 3 15:55:58.263: RT: delete subnet route to 1.1.1.0/24A few seconds later, the route will be installed again in the routing table:
R2#show ip route rip
1.0.0.0/24 is subnetted, 1 subnets
R 1.1.1.0 [120/6] via 192.168.12.1, 00:00:01, FastEthernet0/0Whatever R1 advertises during the holddown, R2 just doesn’t care…it will flush it anyway.
Lower metric from R3 during holddown time
What if the source is different? What if R3 advertises 1.1.1.0 /24 while it’s in holddown on R2? Only one way to find out…
R1(config)#interface FastEthernet 0/0
R1(config-if)#shutdownWe will have to wait until the route goes into holddown:
R2#
Sep 3 16:03:48.263: RT: delete route to 1.1.1.0 via 192.168.12.1, rip metric [120/6]
Sep 3 16:03:48.263: RT: no routes to 1.1.1.0, entering holddownWhile the route is in holddown, I’ll quickly add a loopback on R3 and advertise it in RIP:
R3(config)#interface loopback 0
R3(config-if)#ip address 1.1.1.1 255.255.255.0
R3(config)#router rip
R3(config-router)#network 1.0.0.0Here we can see that R3 is advertising it to R2:
R3#
Sep 3 16:04:07.291: RT: updating connected 1.1.1.0/24 (0x0): via 0.0.0.0 Lo0
Sep 3 16:04:07.291: RT: add 1.1.1.0/24 via 0.0.0.0, connected metric [0/0]
Sep 3 16:04:07.291: RT: interface Loopback0 added to routing table
Sep 3 16:04:07.291: RIP: sending request on Loopback0 to 224.0.0.9
Sep 3 16:04:07.291: RT: updating connected 1.1.1.1/32 (0x0): via 0.0.0.0 Lo0
Sep 3 16:04:07.291: RT: network 1.0.0.0 is now variably masked
Sep 3 16:04:07.291: RT: add 1.1.1.1/32 via 0.0.0.0, connected metric [0/0]
Sep 3 16:04:07.299: RIP: ignored v2 packet from 1.1.1.1 (sourced from one of our addresses)
Sep 3 16:04:09.295: RIP: sending v2 flash update to 224.0.0.9 via FastEthernet0/0 (192.168.23.3)
Sep 3 16:04:09.295: RIP: build flash update entries
Sep 3 16:04:09.295: 1.1.1.0/24 via 0.0.0.0, metric 1, tag 0What does R2 think of this very attractive route?
R2#
Sep 3 16:04:17.759: RIP: received v2 update from 192.168.23.3 on FastEthernet0/1
Sep 3 16:04:17.759: 1.1.1.0/24 via 0.0.0.0 in 1 hops
Sep 3 16:04:17.759: RT: updating rip 1.1.1.0/24 (0x0): via 192.168.23.3 Fa0/1R2 receives it but really doesn’t care about it..the route will remain in holddown:
R2#show ip route rip
1.0.0.0/24 is subnetted, 1 subnets
R 1.1.1.0/24 is possibly down,Once another 60 seconds have expired, the flush timer will be expired and the route is flushed:
R2#
Sep 3 16:04:48.263: RT: delete subnet route to 1.1.1.0/24Only then R2 will install the information from R3 in its routing table:
R2#show ip route rip
R 1.1.1.0 [120/1] via 192.168.23.3, 00:00:14, FastEthernet0/1Now we know that nothing will stop the holddown timer, lower metrics and different sources don’t matter.
Increase the flush timer
What will happen when the holddown timer expires while the flush timer is still active? So far we haven’t been able to see this since the holddown timer doesn’t have enough time to expire, the flush timer kills it.
To test this, I will increase the flush timer to 400 seconds (reducing the holddown timer will also do the job). Let’s do this:
R2(config)#router rip
R2(config-router)#timers basic 30 180 180 400Let’s shut R3 so that the route goes in holddown again:
R3(config)#interface FastEthernet 0/0
R3(config-if)#shutdown180 seconds later the invalid timer expires and we go in holddown:
R2#
Sep 3 16:20:38.263: RT: delete route to 1.1.1.0 via 192.168.23.3, rip metric [120/1]
Sep 3 16:20:38.263: RT: no routes to 1.1.1.0, entering holddownNow we can enjoy 180 seconds of holddown time…let’s enable the interface on R3 again:
R3(config)#interface FastEthernet 0/0
R3(config-if)#no shutdownDuring this time, R2 will receive updates from R3:
R2#
Sep 3 16:22:12.375: RIP: received v2 update from 192.168.23.3 on FastEthernet0/1
Sep 3 16:22:12.375: 1.1.1.0/24 via 0.0.0.0 in 1 hopsLike we have seen before, it doesn’t care about these updates as long as it’s in holddown:
R2#show ip route rip
1.0.0.0/24 is subnetted, 1 subnets
R 1.1.1.0/24 is possibly down,180 seconds later, the holddown timer is expired. The router doesn’t produce a message when it expires but you will see something happen when we receive another update from R3:
Hi Rene,
I’ve been waiting for your debugging, Thank you very much about this, that’s was very Interesting to me.
Can you also do debugging about Flash Update Threshhold timer and Sleep Timer, please?
If I have some spare time I’ll see if I can debug these two.
The flash update threshold timer is apparently used to suppress the flash update (triggered update) when it’s X seconds within the scheduled routing update (which is sent every 30 seconds).
The sleeptime is a funny one…it sets the delay in milliseconds how long we wait to send the scheduled routing update when a flash update is sent. I looked around for this and even though the RIP command supports it, it doesn’t seem to work.
Rene
Brilliant as always, the Cisco docs are just confusing, thanks for this clarification.
Rene,
that’s a very detailed explanation. Thanks buddy, you are genius
Ammar,
Awesome article. I have a question though: what happens if you change the timer for a router and not for others? While it’s better to have same timers; still, since no adjacency is needed to form, is it recommended if you change timer on one device only? I had seen such case where you have linux (unmanaged) router on one end and CISCO router at other and update timer being shortened in CISCO router only. Not sure about the consequences, then. Any thoughts?
-Deep