Lesson Contents
Rapid Spanning Tree Protocol (RSTP) is an improved version of the original (classic) Spanning Tree Protocol, which has much faster convergence times. This is possible because it uses a new negotiation mechanism with proposal/agreement handshakes that the classic STP doesn’t have. Classic STP takes 30-50 seconds to converge after a link failure, and RSTP can converge in under 6 seconds.
In this lesson, we’ll take a look at how RSTP works, its port states and roles, the new sync mechanism and how it’s able to converge much faster than classic STP.
Key Takeaways
- Classic STP has these port states:
- Blocking
- Listening
- Learning
- Forwarding
- RSTP uses three port states:
- Discarding (blocking and listening are combined)
- Learning
- A Proposal/agreement mechanism replaces the timer-based convergence.
- All switches generate BPDUs every hello time (2 seconds), not just the root bridge.
- BPDUs work as keepalives. If a switch misses 3 BPDUs, it assumes the neighbor has failed.
- UplinkFast is built in, so alternate ports immediately become active when the root port fails.
- Topology changes only trigger when non-edge ports move to forwarding, not on link failures.
- RSTP is backward compatible with classic STP, but falls back to slower convergence on links that connect to classic STP switches
- Edge ports (portfast) and point-to-point links (full duplex) enable fast convergence
Prerequisites
To understand RSTP, you should understand how classic STP works. This is explained in the introduction to Spanning Tree lesson.
Port States
Let’s start with the port states. Take a look at the picture below:
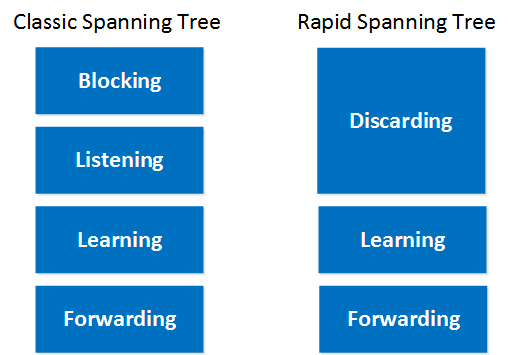
Remember the port states of classic STP? We have a blocking, listening, learning, and forwarding port state. This is the first difference between the spanning tree and the rapid spanning tree. Rapid spanning tree only has three port states:
- Discarding
- Learning
- Forwarding
You already know about learning and forwarding, but discarding is a new port state. Basically, it combines the blocking and listening port states. Here’s an overview:
| Classic Spanning Tree | Rapid Spanning Tree | Port active in topology? | Learns MAC addresses? |
| Blocking | Discarding | No | No |
| Listening | Discarding | Yes | No |
| Learning | Learning | Yes | Yes |
| Forwarding | Forwarding | Yes | Yes |
Port Roles
Do you remember all the other port roles that spanning tree has? Let’s do a little review, and I’ll show you what is different for rapid spanning tree:
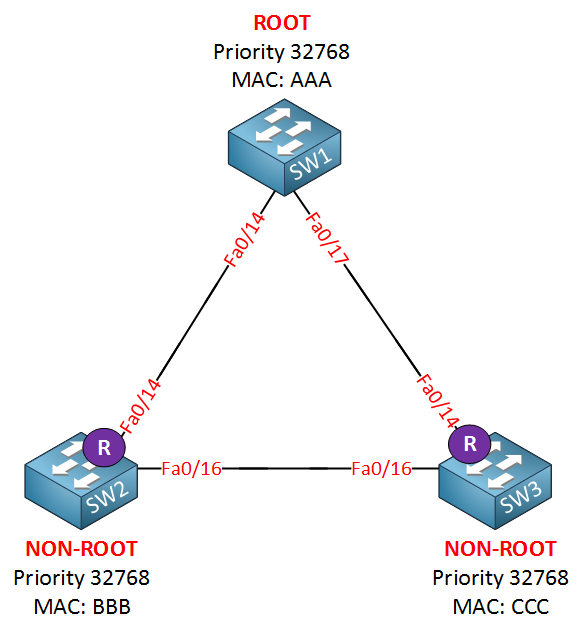
The switch with the best bridge ID (priority + MAC address) becomes the root bridge. The other switches (non-root) have to find the shortest cost path to the root bridge. This is the root port. Nothing new here, this works the same for rapid spanning tree. The next step is to select the designated ports:
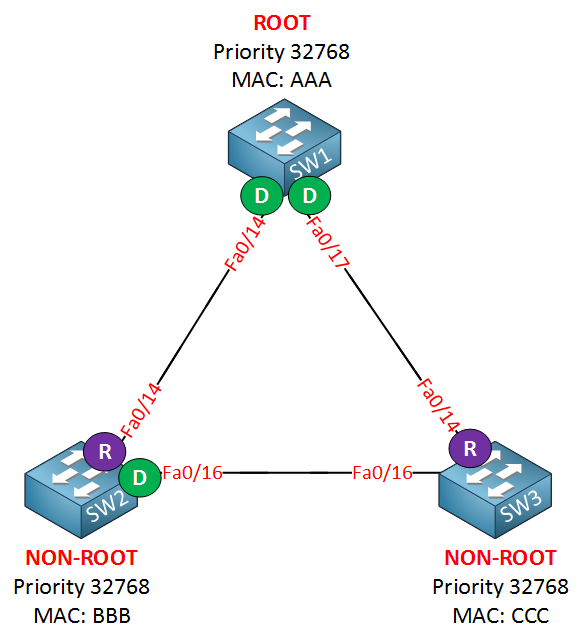
On each segment, there can be only one designated port, or we’ll end up with a loop. The port will become the designated port if it can send the best BPDU. SW1 as a root bridge will always have the best ports so all of interfaces will be designated. The fa0/16 interface on SW2 will be the designated port in my example because it has a better bridge ID than SW3. There’s still nothing new here compared to the classic spanning tree. The interfaces that are left will be blocked:
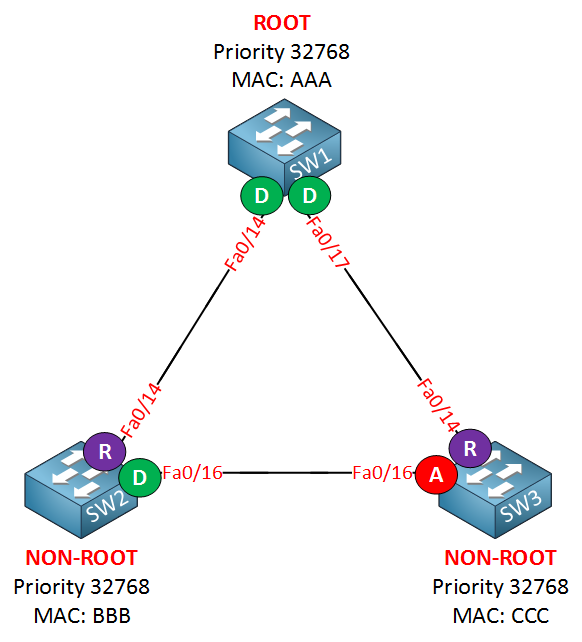
SW3 receives better BPDUs on its fa0/16 interface from SW2, and thus it will be blocked. This is the alternate port, and it’s still the same thing for rapid spanning tree. Let me show you a new example with a port state that is new for rapid spanning tree:
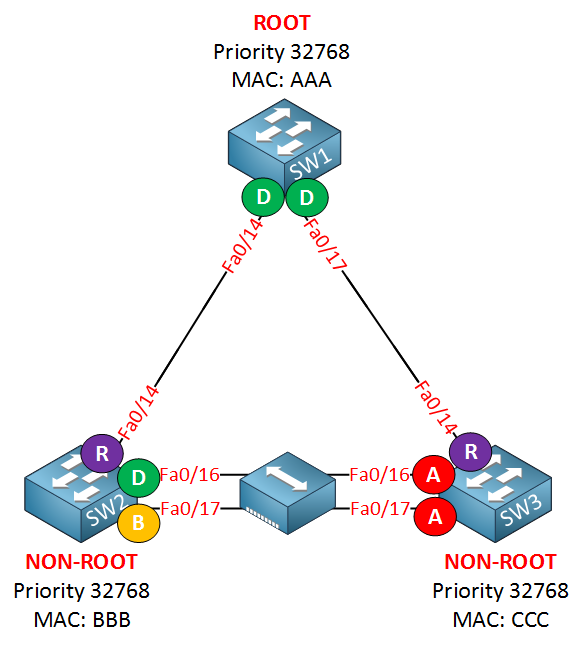
Here is a new port for you. Take a look at the fa0/17 interface of SW2. It’s called a backup port, and it’s new for rapid spanning tree. You are very unlikely to see this port on a production network, though. Between SW2 and SW3, I’ve added a hub. Normally (without the hub in between) both fa0/16 and fa0/17 would be designated ports.
Because of the hub, the fa0/16 and fa0/17 interface on SW2 are now in the same collision domain. Fa0/16 will be elected as the designated port, and fa0/17 will become the backup port for the fa0/16 interface. The reason that SW2 sees the fa0/17 interface as a backup port is because it receives its own BPDUs on the fa0/16 and fa0/17 interfaces and understands that it has two connections to the same segment. If you remove the hub, the fa0/16 and fa0/17 will both be designated ports, just like the classic spanning tree.
BPDU
Something else that is different is the BPDU, take a look:
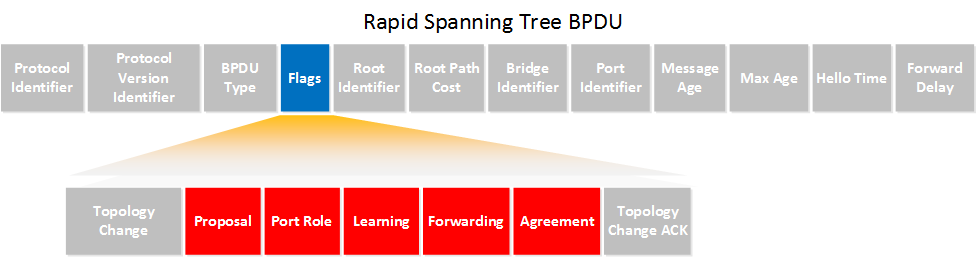
The BPDU is different for rapid spanning tree. In the classic spanning tree, the flags field only had two bits in use:
- Topology change.
- Topology change acknowledgment.
All bits of the flag field are now used. The role of the port that originates the BPDU will be added by using the port role field, it has the following options:
- Unknown
- Alternate / Backup port.
- Root port.
- Designated port.
This new BPDU is called a version 2 BPDU. Switches running the old version of spanning tree will drop this new BPDU version. In case you are wondering…rapid spanning tree and the old spanning are compatible! Rapid spanning tree has a way of dealing with switches running the older spanning tree version.
Let’s walk through the other stuff that has been changed:
BPDUs are now sent every hello time. Only the root bridge generated BPDUs in the classic spanning tree, and those were relayed by the non-root switches if they received it on their root port. Rapid spanning tree works differently…all switches generate BPDUs every two seconds (hello time). This is the default hello time, but you can change it.
The classic spanning tree uses a max age timer (20 seconds) for BPDUs before they are discarded. Rapid spanning tree works differently! BPDUs are now used as a keepalive mechanism similar to what routing protocols like OSPF or EIGRP use. If a switch misses three BPDUs from a neighbor switch, it will assume connectivity to this switch has been lost, and it will remove all MAC addresses immediately.
Rapid spanning tree will accept inferior BPDUs. The classic spanning tree ignores them. Does this ring a bell? This is pretty much the backbone fast feature of classic spanning tree.
Transition speed (convergence time) is the most important feature of rapid spanning tree. The classic spanning tree had to walk through the listening and learning state before moving an interface to the forwarding state. This took 30 seconds with the default timers. The classic spanning tree was based on timers.
Rapid spanning doesn’t use timers to decide whether an interface can move to the forwarding state or not. It will use a negotiation mechanism for this. I’ll show you how this works in a bit.
Do you remember portfast? If we enable portfast while running the classic spanning tree it will skip the listening and learning state and put the interface in the forwarding state right away. Besides moving the interface to the forwarding state it will also not generate topology changes when the interface goes up or down. We still use portfast for rapid spanning tree, but it’s now referred to as an edge port.
Rapid spanning tree can only put interfaces in the forwarding state really fast on edge ports (portfast) or point-to-point interfaces. It will take a look at the link type, and there are only two link types:
- Point-to-point (full duplex)
- Shared (half duplex)
Normally we are using switches, and all our interfaces are configured as full duplex, rapid spanning tree sees these interfaces as point-to-point. If we introduce a hub to our network, we’ll have half duplex, which is seen as a shared interface to rapid spanning tree.
Negotiation
Let’s take a close look at the negotiation mechanism that I described earlier:
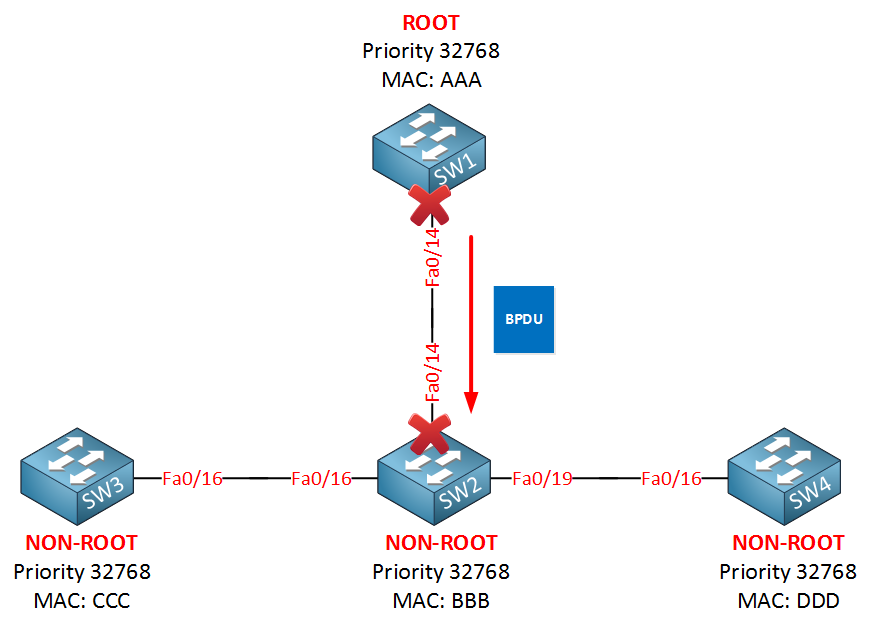
Let me describe the rapid spanning tree synchronization mechanism by using the picture above. SW1 on top is the root bridge. SW2, SW3, and SW4 are non-root bridges.
As soon as the link between SW1 and SW2 comes up, their interfaces will be in blocking mode. SW2 will receive a BPDU from SW1, and now a negotiation will take place called sync:
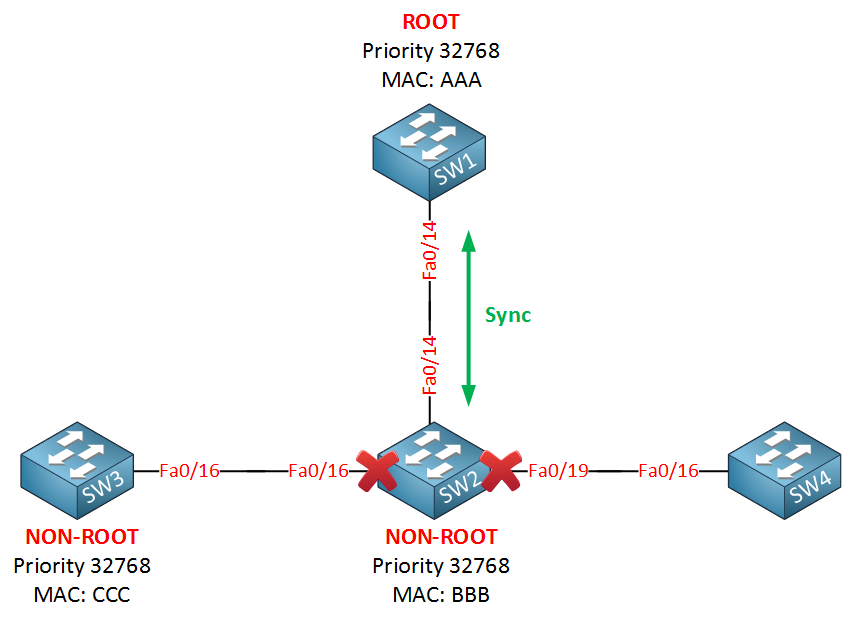
After SW2 receives the BPDU from the root bridge, it immediately blocks all its non-edge designated ports. Non-edge ports are the interfaces that connect to other switches, while edge ports are the interfaces that have portfast configured. As soon as SW2 blocks its non-edge ports, the link between SW1 and SW2 will go into forwarding state. SW2 will now do the following:
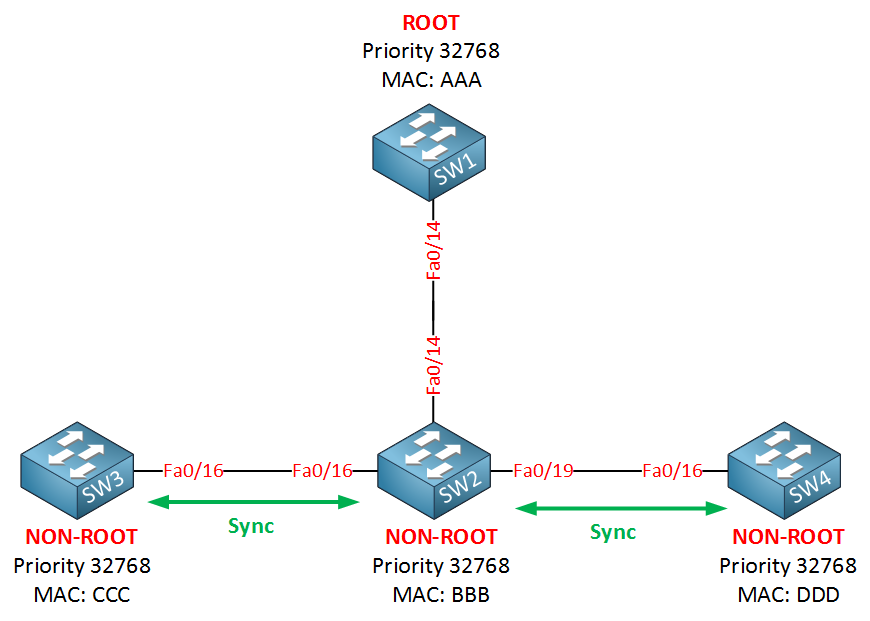
SW2 will also perform a sync operation with both SW3 and SW4 so they can quickly move to the forwarding state.
Are you following me so far? The lesson to learn here is that rapid spanning tree uses this sync mechanism instead of the “timer-based” mechanism that the classic spanning tree uses (listening > learning > forwarding). I’m going to show you what this looks like on real switches in a bit. Let’s take a closer look at the sync mechanism. Let’s look at what happens exactly between SW1 and SW2:
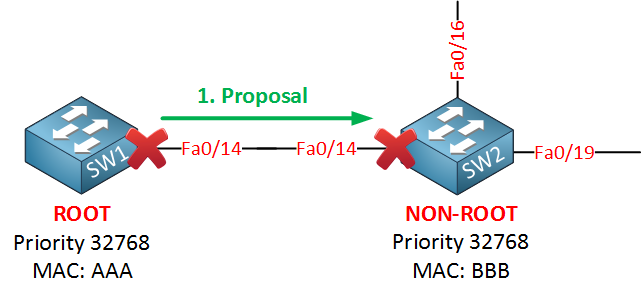
At first, the interfaces will be blocked until they receive a BPDU from each other. At this moment, SW2 will figure out that SW1 is the root bridge because it has the best BPDU information. The sync mechanism will start because SW1 will set the proposal bit in the flag field of the BPDU. When SW2 receives the proposal, it has to do something with it:
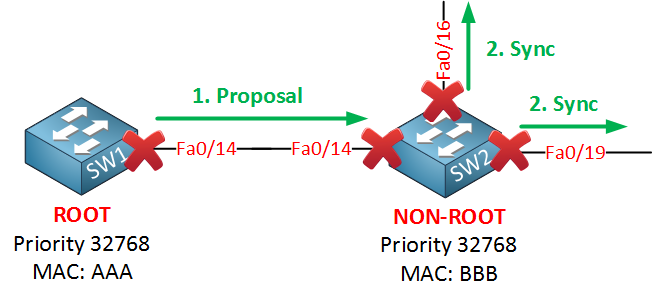
SW2 will block all its non-edge interfaces and will start the synchronization towards SW3 and SW4. Once this is done, SW2 will let SW1 know about this:
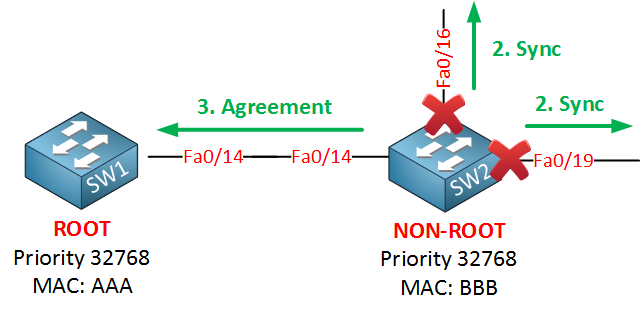
Once SW2 has its interfaces in sync mode, it will let SW1 know about this by sending an agreement. This agreement is a copy of the proposal BPDU where the proposal bit has been switched off, and the agreement bit is switched on. The fa0/14 interface on SW2 will now go into forwarding mode. When SW1 receives the agreement, here’s what happens:
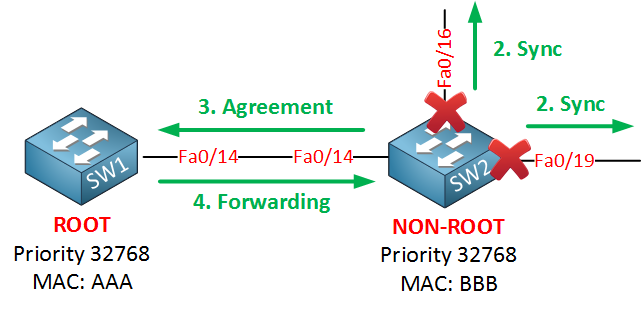
Once SW1 receives the agreement from SW2, it will put its fa0/14 interface in forwarding mode immediately.
What about the fa0/16 and fa0/19 interface on SW2?
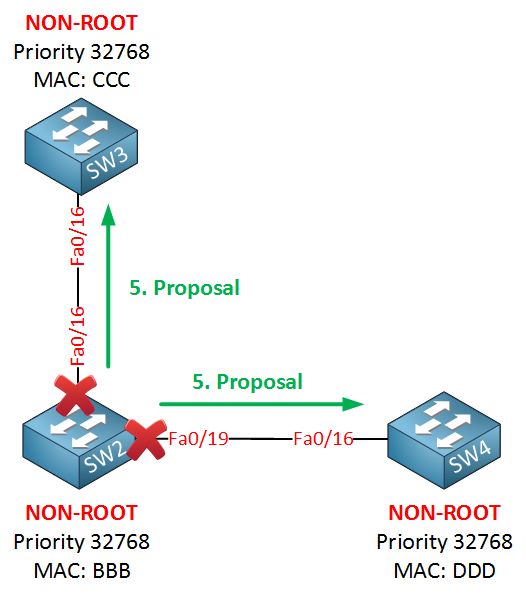
The exact same sync mechanism will take place now on these interfaces. SW2 will send a proposal on its fa0/16 and fa0/19 interfaces to SW3 and SW4. SW3 and SW4 will send an agreement:
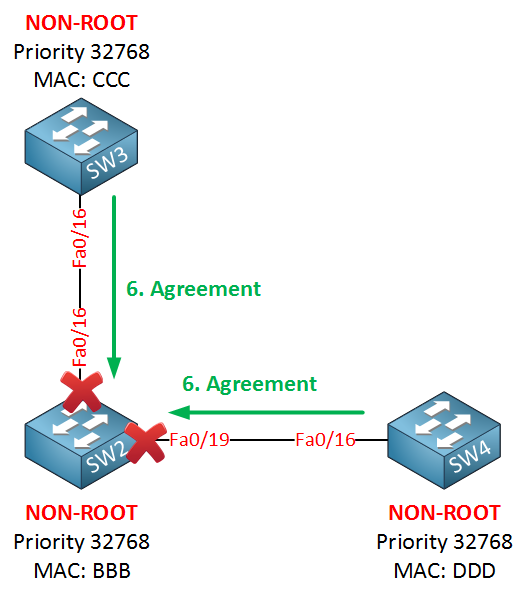
SW3 and SW4 don’t have any other interfaces, so they will send an agreement back to SW2:
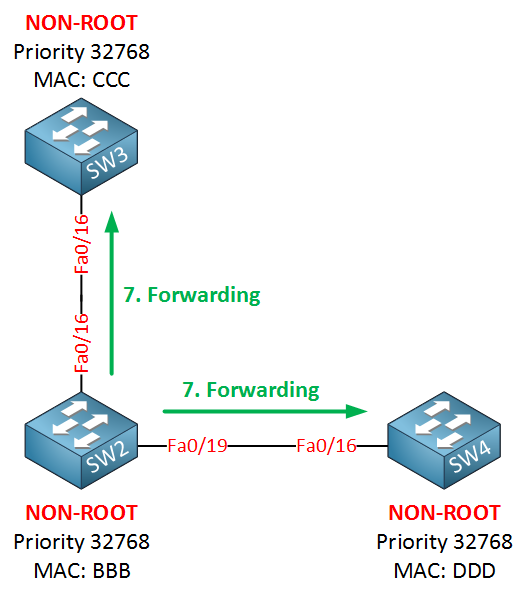
SW2 will place its fa0/16 and fa0/19 interface in forwarding, and we are done. This sync mechanism is just a couple of messages flying back and forth and very fast. It’s much faster than the timer-based mechanism of the classic spanning tree!
What else is new with rapid spanning tree? There are three more things I want to show you:
- UplinkFast
- Topology change mechanism.
- Compatibility with classic spanning tree.
When you configure the classic spanning tree, you have to enable UplinkFast yourself. Rapid spanning tree uses UpLinkFast by default. You don’t have to configure it yourself. When a switch loses its root port, it will put its alternate port in forwarding immediately.
The difference is that the classic spanning tree needed multicast frames to update the MAC address tables of all switches.
We don’t need this anymore because the topology change mechanism for rapid spanning tree is different. So, what’s different about the topology change mechanism?
With the classic spanning tree, a link failure would trigger a topology change. Using rapid spanning tree, a link failure is not considered as a topology change. Only non-edge interfaces (leading to other switches) that move to the forwarding state are considered as a topology change. Once a switch detects a topology change, this will happen:
- It will start a topology change while timer with a value that is twice the hello time. This will be done for all non-edge designated and root ports.
- It will flush the MAC addresses that are learned on these ports.
- As long as the topology changes while the timer is active, it will set the topology change bit on BPDUs that are sent out these ports. BPDUs will also be sent out of its root port.
When a neighbor switch receives this BPDU with the topology change bit set, this will happen:
- It will clear all its MAC addresses on all interfaces except the one where it received the BPDU with the topology change.
- It will start a topology change while timer itself and send BPDUs on all designated ports and the root port, setting the topology change bit.

Instead of sending a topology change all the way up to the root bridge as the classic spanning tree does, the topology change is now quickly flooded throughout the network. If you want to know exactly how this topology change mechanism works, then take a look at this lesson.
Thank you very much
You are welcome Raed!
Wow. Excellent lesson. Very clear and to the point. I am definetly enjoying this site and learning. Excellent refresher cource !
Please keep up the great work. BTW…Yes I am recommonding this site.
Glad to hear you like it!
Excellent explanation!