Lesson Contents
Imagine you have a large network that has many switches and routers, a dozen servers and hundreds of workstations…wouldn’t it be great if you could monitor all those devices somehow? Using a NMS (Network Management System) it’s possible to monitor all devices in your network. Whenever something bad happens (like an interface that goes down) you will receive an e-mail or text message on your phone so you can respond to it immediately.
Sounds good?
Back in the 80s, some smart folks figured out that we should have something to monitor all IP based network devices. The idea was that most devices like computers, printers, and routers share some characteristics. They all have an interface, an IP address, a hostname, buffers and so on.
They created a database with variables that could be used to monitor different items of network devices and this resulted in SNMP (Simple Network Management Protocol).
SNMP runs on the application layer and consists of a SNMP manager and a SNMP agent. The SNMP manager is the software that is running on a pc or server that will monitor the network devices, the SNMP agent runs on the network device.

The database that I just described is called the MIB (Management Information Base) and an object could be the interface status on the router (up or down) or perhaps the CPU load at a certain moment. An object in the MIB is called an OID (Object Identifier).
The SNMP manager will be able to send periodic polls to the router and it will store this information. This way it’s possible to create graphs to show you the CPU load or interface load from the last 24 hours, week, month or whatever you like.
It’s also possible to configure your network devices through SNMP. This might be useful to configure a large number of switches or routers from your network management system so you don’t have to telnet/ssh into each device separately to make changes.
The packet that we use to poll information is called a SNMP GET message and the packet that is used to write a configuration is a SNMP SET message.
Network Management System
To give you an example of what a NMS looks like, I’ll show you some screenshots of Observium.
Observium is a free SNMP based network monitoring platform which can monitor Cisco, Linux, Windows and some other devices. It’s easy to install so if you never worked with SNMP or monitoring network devices before I can highly recommend giving it a try. You can download it at https://www.observium.org/.
Here’s what it looks like:
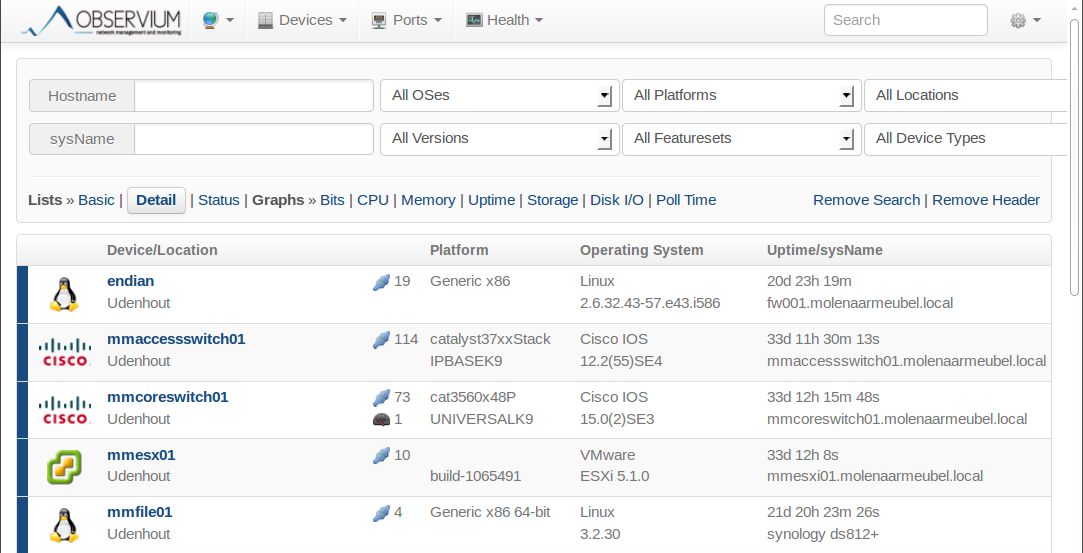
Above you see an overview of all the devices that our NMS manages. There are two linux devices, two Cisco devices and there’s a VMWare ESXi server. You can see the uptime of all devices.
Let’s take a closer look at one of the Cisco devices:
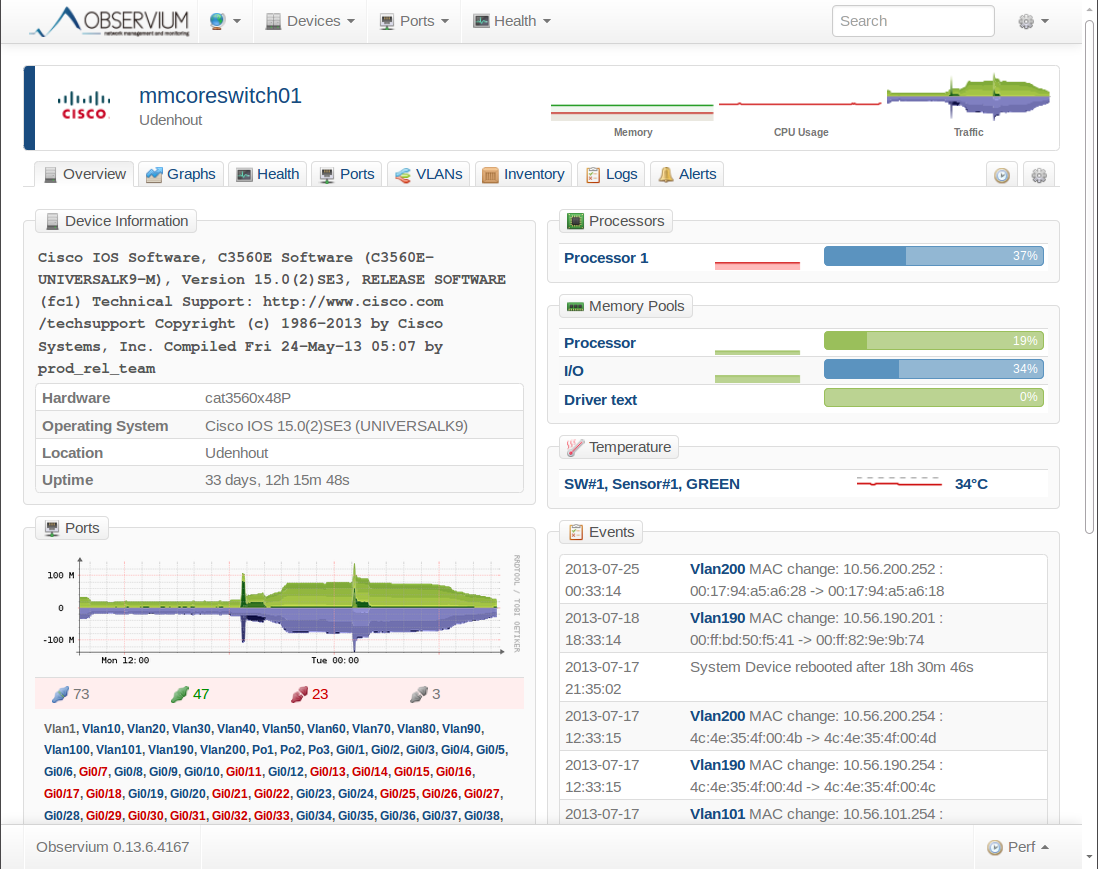
This switch is called “mmcoreswitch01” and it’s a Cisco Catalyst 3560E. It gives us a nice overview of the CPU load, the temperature and the interfaces that are up or down.
Let’s take a closer look at the temperature of this switch:
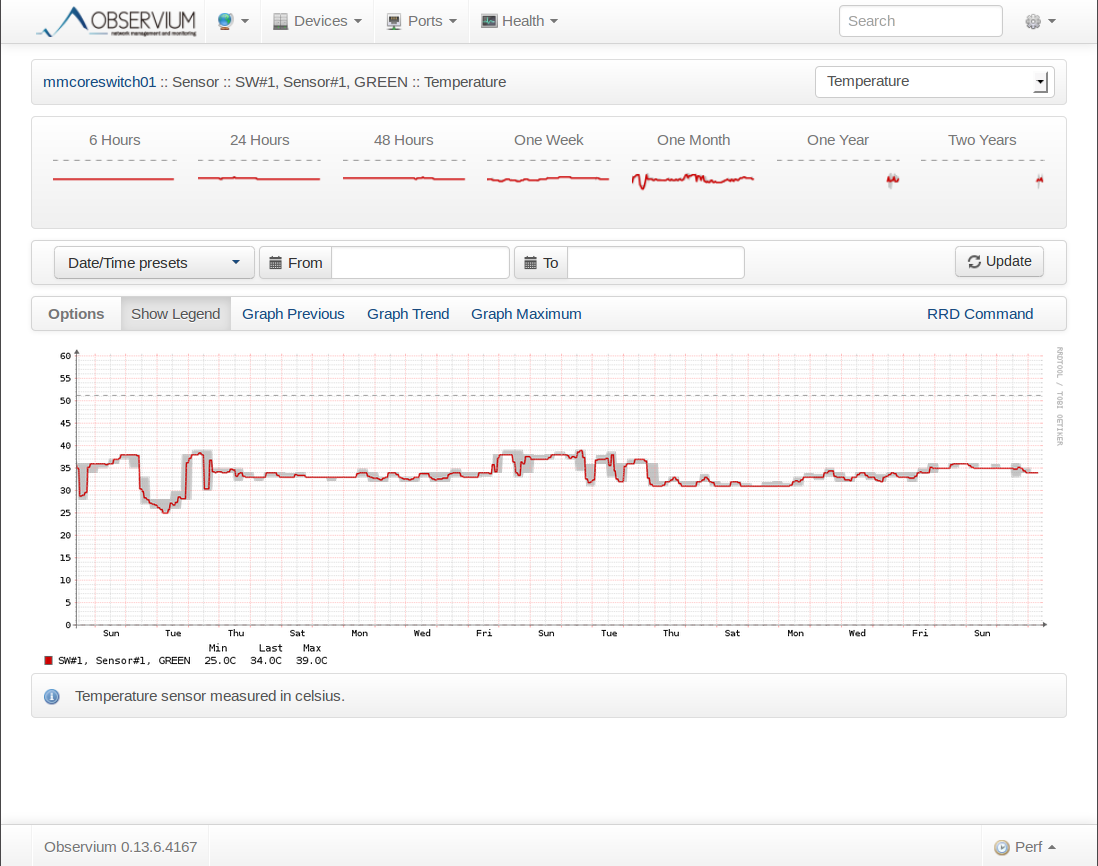
Here’s the temperature of this switch from the last month. When the temperature exceeds a certain value (let’s say 50 degrees Celcius) then we can tell our NMS to send us an e-mail.
Let’s take a look at an interface of this switch:
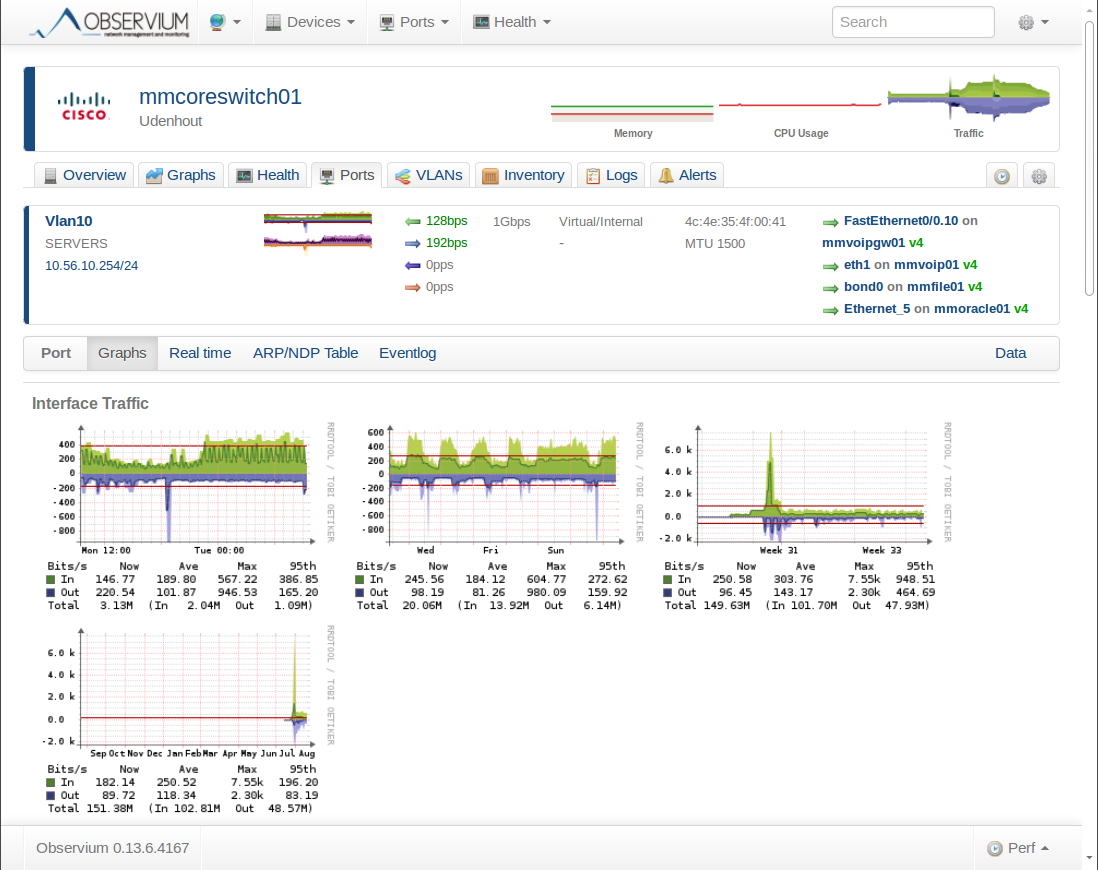
Here’s an overview of the VLAN 10 interface. You can see how much traffic is sent and received on this interface. We can zoom in one one the graphs if we want:
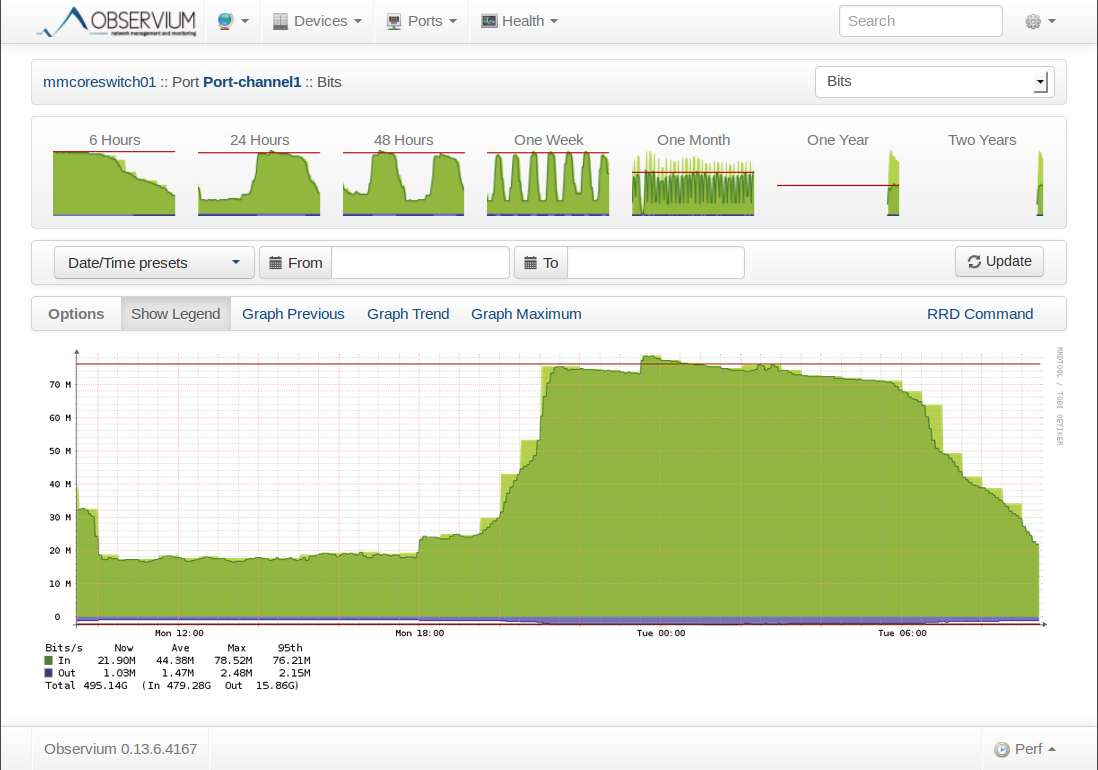
This gives a nice overview of how much traffic was sent in the last 24 hours of this particular interface.
I hope this gives you an idea of what a NMS looks like and why this might be useful. If you want to take a look at Observium yourself you can use the live demo on their website:
SNMP Messages
All the information that Observium shows us is retrieved by using SNMP GET messages:
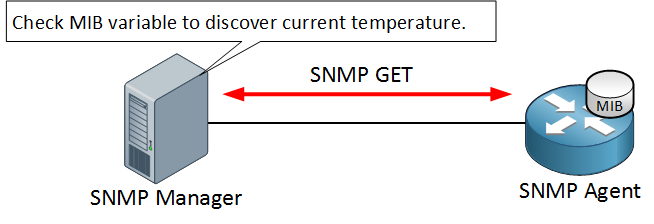
The NMS will send SNMP GET messages to request the current state of certain OIDs every few minutes or so. This is great for monitoring the temperature or traffic statistics but the downside of using these SNMP GET messages is that it might take a few minutes for the NMS to discover that an interface is down.
Besides using SNMP GET messages, a SNMP agent can also send SNMP traps. A trap is a notification that it sent immediately as soon as something occurs, for example, an interface that goes down:
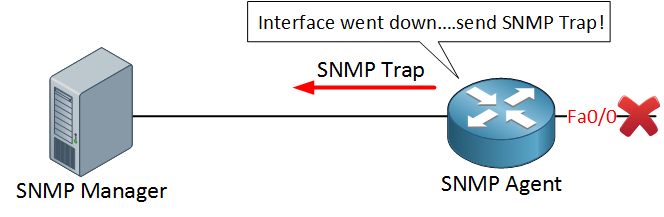
As soon as something bad happens (like the interface that goes down) the SNMP agent will send a SNMP trap immediately to the NMS. The NMS will respond by sending you an e-mail, text message or a notification on the screen.
These SNMP trap messages sound like a good idea but there’s one problem with them…there is no acknowledgment for the SNMP trap, so you never know if the trap made it to the NMS or not. SNMP version 3 deals with this problem with an alternative message which uses an acknowledgment called the inform message.
OID (Object Identifier)
We can use a NMS to monitor one of our network devices but how do we exactly know what to monitor? There are so many things we could check for…a single interface on a router has over 20 things we could check: input/output errors, sent/received packets, interface status, and so on. Each of these things to check has a different OID (Object Identifier).
Since there are so many OIDs, the MIB is organized into a hierarchy that looks like a tree. In this tree, you will find a number of branches with OIDs that are based on RFC standards but you will also find some vendor specific variables. Cisco, for example, has variables to monitor EIGRP and other Cisco protocols.
Let me give you an example of this tree by showing where the ‘hostname’ and ‘domainname’ objects are located.
Great lesson! I had to implement an SNMP change control recently. Nice to have a great refresher.
good explaination
Fahad ALFadani
KSA
The tip for Observium is really helpful, thanks!
Hi Wilfried,
You might also like LibreNMS.
It’s the exact same thing as Observium but it’s free. It supports instant updates and alerting out of the box. For Observium you’ll have to pay when you want automatic updates and alerting.
Rene
Hi Rene,
What is the difference between SNMP get and get next?