Lesson Contents
Cloud computing has become increasingly popular over the years. Large cloud providers like Amazon AWS, Microsoft Azure, and Google Cloud have many data centers throughout the world. Data centers are the perfect place for our servers, storage, and network devices. They offer optimal cooling, redundant power, and security.
Cloud computing has many advantages, including:
- Scalability: you can get as much computing power and storage as you need. It’s on-demand so you only pay for the resources you need. You can scale up and down, in or out when needed.
- High availability: cloud providers offer multiple regions throughout the world. Each region has multiple availability zones.
- Cost: with cloud computing you pay exactly for the resources you need. When you take high availability into consideration, cloud computing is often cheaper than on-premises solutions.
There are, however, some problems when we use cloud services for IoT:
- High latency: many IoT applications require low latency. This is something the cloud can’t always offer because of the distance between our devices and the closest cloud data center.
- Downtime: we need an Internet connection to reach the cloud. There can be issues with your Internet connection or the cloud provider. It’s unlikely that a major cloud provider has outages, but it has happened with Amazon AWS and Microsoft Azure in the past. The Internet connection might be inconsistent. This could happen with cars, airplanes, and ships.
- Bandwidth: we may need to transmit more data from our devices than we have the bandwidth for.
- Security: we send private data through an Internet connection to a cloud provider. Cloud providers offer a shared platform. How secure is your data? Cloud providers are also vulnerable to attacks. Your company might be bound by law so you are not allowed to use any cloud platforms. We can partially solve this with hybrid or private clouds.
Let me give you a real life example. Imagine we have a self-driving car with cameras and sensors that measure acceleration and deceleration.
The car continuously sends sensor data and live streams from the camera to the cloud. Suddenly, a pedestrian tries to cross the street. The car has to make a crucial decision: hit the brakes or steer to the left or right to prevent a collision.
It might take too long to send the data from our car, to the cloud, and back to the car. This is a latency problem. The car moves around so there might not be a consistent Internet connection or enough bandwidth available (downtime and bandwidth problems).
We require basic processing and temporal storage in the car, not in the cloud.
To solve these cloud problems, we can use two solutions:
- Fog computing
- Edge computing
Let’s look at both options.
Fog Computing
Fog computing solves some of the cloud problems we talked about. With fog computing, we move some intelligence, compute, and storage resources from the cloud back to the local network. This allows us to locally process and analyze data in fog nodes or IoT devices.
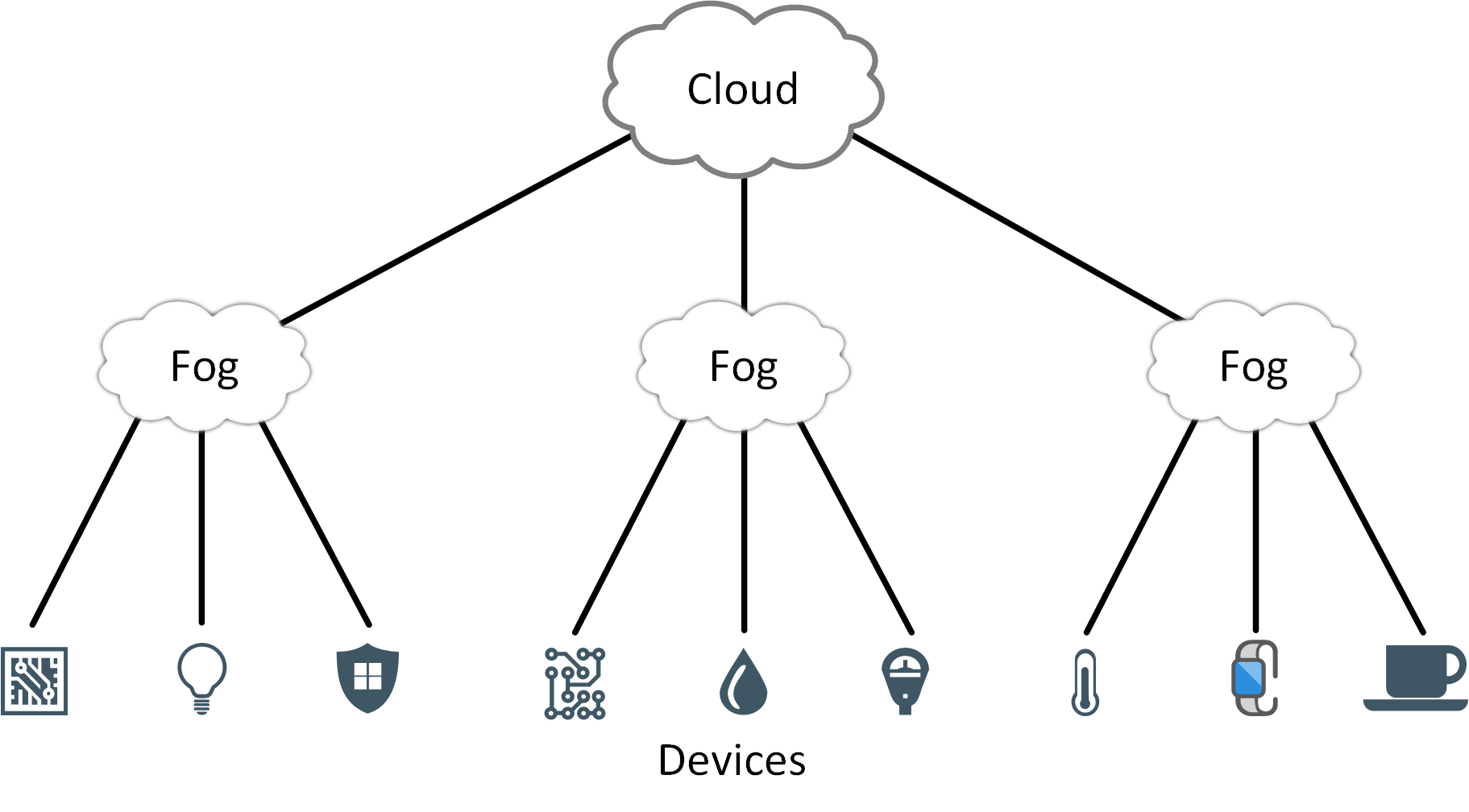
Cisco came up with the term “fog computing”. It’s called fog computing because we use it close to the “ground” (data from our devices on our local network). The cloud is the exact opposite, it’s far away from our data and devices.
Fog computing supports low latency, high bandwidth, and increased security. It reduces the amount of northbound traffic to the cloud provider.
How do we reduce the amount of northbound traffic?
Traditional data compression algorithms on the network layer are usually data de-duplication algorithms. They examine packets and look for patterns in incremental sizes. For example: 4 Kb, 8 Kb, 16 Kb, etc.). For each pattern, they create a signature. When the algorithm sees the same pattern again, it replaces the pattern with a signature. This reduces the size of the packet while the original payload remains the same.
We can reduce the amount of data even further through analysis. Let’s look at an example.
We have a device with a temperature sensor which reports the temperature value every 10 seconds. The packet includes the IP address of the device, the temperature, and a timestamp.
One packet of 5 Kb every 10 seconds means we transmit 5 Kb x 6 = 30 Kb every minute. In an hour, that’s 30 Kb x 60 = 1800 Kb (1.8 Mb).
Instead of sending these packets directly from the device to the cloud, we add a fog node in between. The fog node only forwards packets to the cloud when the temperature changes. If the temperature doesn’t change within a minute, then we only send 1 packet of 5 Kb to the cloud instead of 5 Kb x 6 = 30 Kb. If the temperature doesn’t change in an hour, then we only send 1 packet of 5 Kb instead of 5 Kb x 6 x 60 = 1800 Kb.
We can go one step further and add a level of hierarchy with fog nodes. Let’s say we have a factory with 10,000 sensors. Each fog node receives and summarizes data from 1,000 sensors so we have 10 fog nodes.
Above these 10 fog nodes, we have another fog node which receives data from the 10 fog nodes. This single fog node summarizes the data and periodically forwards the data to the cloud. The fog node also has temporary storage so that when the cloud is temporarily unavailable, we don’t lose our data.
This hierarchical setup gives us an entire view of the factory’s sensor readings while sending a minimal amount of data to the cloud.
You can also use fog nodes for translation or protocol conversion. An example is temperature conversion:
- Temperature sensor from vendor X reports temperature in Fahrenheit.
- Temperature sensor from vendor Y reports temperature in Celsius.
- Temperature sensor from vendor Z reports temperature in Kelvin.
The fog node can translate sensor data in Fahrenheit and Kelvin to Celsius, then forward it to the cloud.
Fog computing is like a middle layer between the cloud and our devices. Without the fog layer, our devices would communicate directly with the cloud. Fog computing has several advantages:
- Lower latency: fog nodes are close to our devices and data.
- Bandwidth: no bandwidth issues since we use the local network. We aggregate data before we send it to the cloud.
- Availability: temporary loss of our connection to the cloud is no problem.
- Cost: we conserve network bandwidth because we don’t send everything to the cloud.
Below are some comparisons between cloud and fog computing. This will help to understand the differences between the two:
- Cloud computing is centralized and consists of large data centers around the world, far away (anywhere between 1-1000 kilometers) from our devices.
- Fog computing is distributed and consists of fog nodes close to our devices.
- Data processing and storage in cloud computing takes place in data centers.
- Data processing and storage in fog computing takes place on our local network.
- The cloud has more computing power and storage capacity than fog computing.
- Cloud computing has a higher latency.
- Fog computing offers low latency.
- We use fog computing for local short-term analysis because it’s faster thanks to low latency. We use cloud computing for long-term deep analysis because it offers more processing power and storage.
Edge Computing
Fog computing has many advantages because the fog layer is close to our devices and data. We can do even better though. Our devices are still “dumb”.