Lesson Contents
We often use Performance, Scalability, and High Availability interchangeably. There are however differences between these three items. In this lesson, we’ll look at their differences regarding the cloud.
Performance
Performance is the throughput of a system under a given workload for a specific time. For an application this could be:
- The time it takes for an application to finish a task. For example, running a query on a database server to fetch all staff records.
- The response time for an application to act upon a user request. For example, a user that requests a webpage.
- A load of a system, measured in the volume of transactions. For example, a web server that processes 500 requests per second.
In the cloud, we validate performance by measurement and testing scalability. Here are examples of items you should measure:
- Resource usage:
- CPU load
- Memory usage
- Disk I/O
- Read/write database queries
- Application statistics
- number of requests
- response time
Performance measurement is an ongoing process, it never ends. You can use the cloud provider‘s tools or external tools.
Performance requirements change when there are new business requirements or when you add new features to your application.
If you use a public cloud, you also need to consider the bandwidth and delay of your WAN connection to the public cloud.
Networklessons.com runs on Amazon AWS. Here are two screenshots of how we measure the performance.
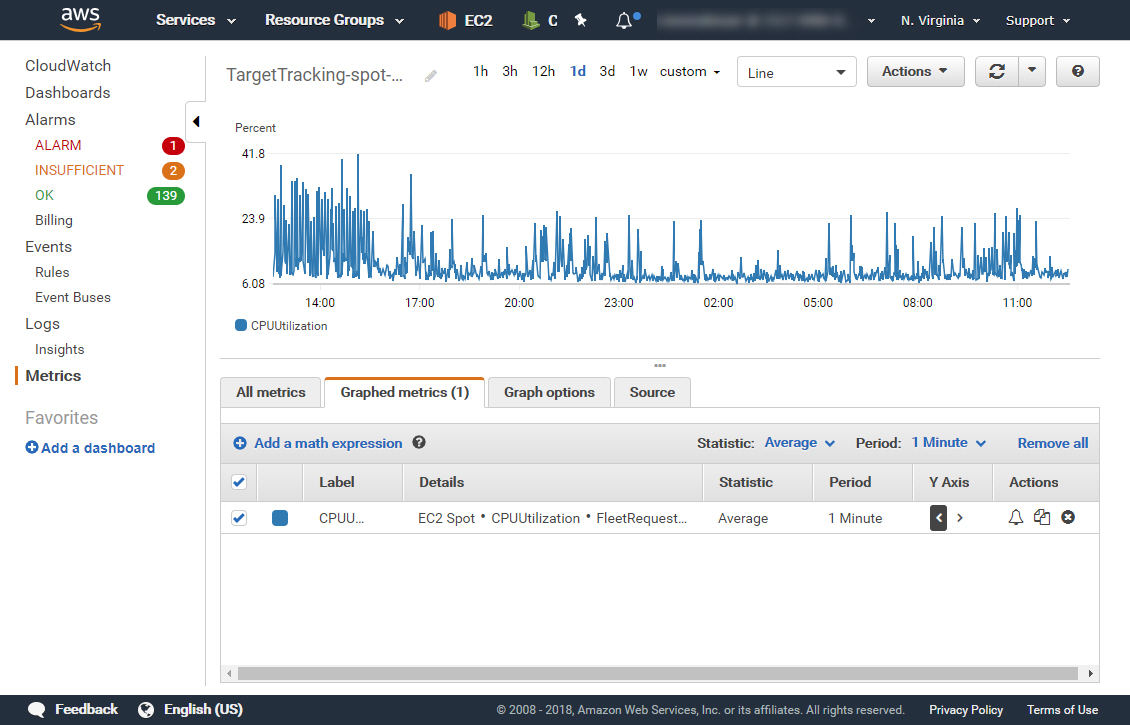
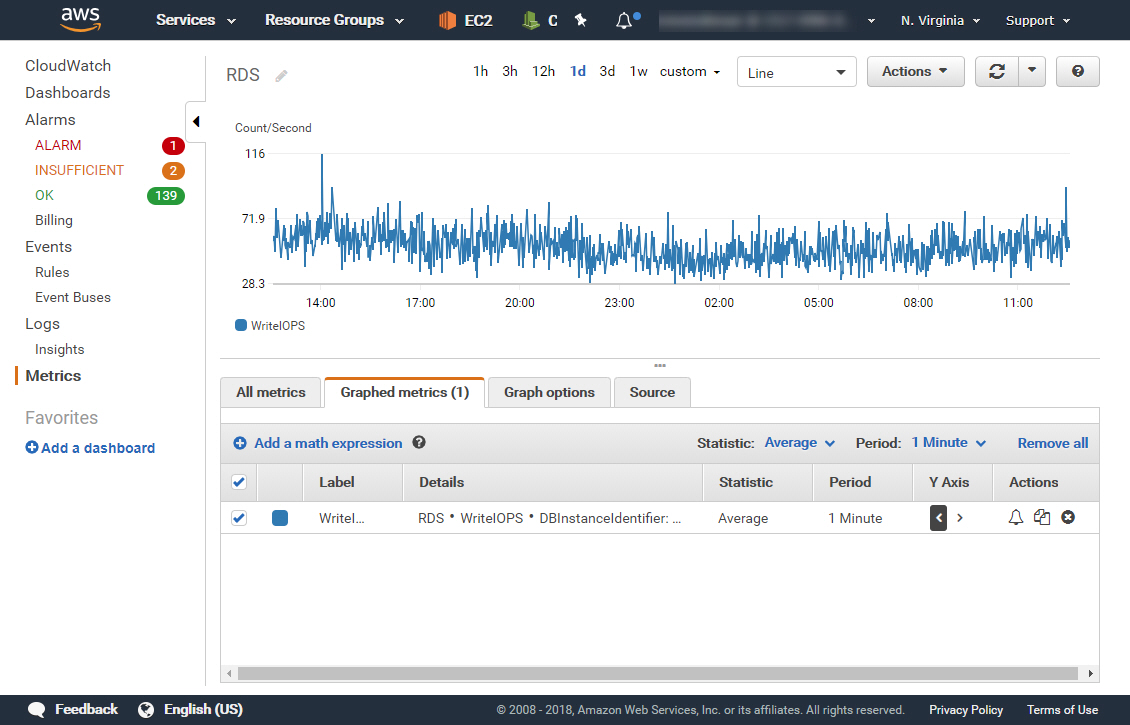
Scalability
Scalability is the ability of a system to handle the increase in demand without impacting the application’s performance or availability.
When the demand is too high and there are not enough resources, then it impacts performance. There are two types of scalability:
- Vertical: scale up or down:
- Add or remove resources:
- CPU
- Memory
- Storage
- Add or remove resources:
- Horizontal: scale out or in:
- Add or remove systems
For example, we can increase the number of CPU cores and memory in a web server (vertical) or we can increase the number of web servers (horizontal).
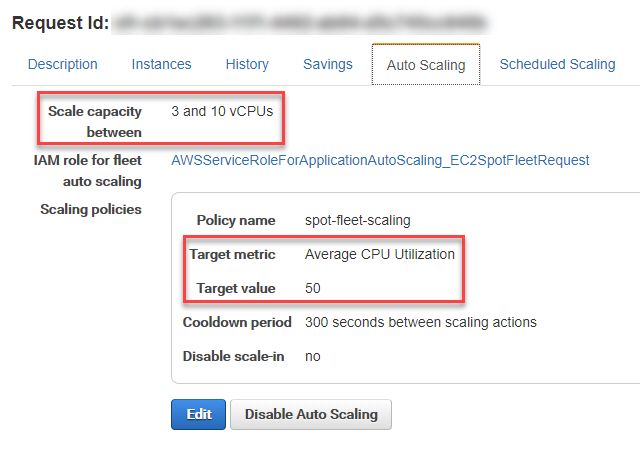
We can scale up horizontally or vertical to prevent lack of resources affecting our performance and availability. Here is a screenshot of the Amazon AWS auto scaling policy we use for networklessons.com web servers:
Elasticity
What if you scale up or out and demand decreases? The advantage of the cloud is that you can scale down or in whenever you want. You pay for the resources you need. We call this elasticity and most cloud providers call it autoscaling. For example:
- Amazon AWS Auto scaling
- Microsoft Azure Autoscale
- Google Cloud Platform Autoscaling
Public cloud providers seem to have an infinite capacity of compute and storage resources. Cloud providers like Amazon AWS, Azure, and Google Cloud need to have enough resources in reserve for their customers. You can bid on their unused capacity with spot instances and save money. However, when someone bids more than you, you lose the instance.
High Availability
High availability (HA) means the application remains available with no interruption.
We achieve high availability when an application continues to operate when one or more underlying components fail. For example, a router, switch, firewall, or server that fails.
We affect HA by implementing the same components on multiple instances (redundancy). For example:
Rene,
Thank you for creating these lessons! I think this is a fantastic topic to cover; a very nice addition to the site.
Cheers,